Improve accuracy with metadata! Explaining metadata and maintenance methods necessary in the age of generative AI


As generative AI becomes more widely used, metadata will become increasingly important for interpreting the context of data. Properly preparing metadata will make it easier to access the necessary information and can also be expected to improve the accuracy of answers. In this article, we will explain why generative AI needs metadata, what kind of metadata should be prepared, and specific preparation methods.
Why Generative AI Needs Metadata
Generative AI is no longer limited to information retrieval, summarization, and translation; as seen in RAGs and AI agents, it is now commonplace to connect to data both inside and outside the company to create added value and improve business efficiency.
The accuracy of generative AI responses depends largely on how well it understands the background and context of the data. Metadata is additional information that indicates the date and time the data was created, its meaning, the department that owns it, and so on, and provides important hints for the AI when learning and responding.
▼The basics of metadata are explained below

What is Metadata? A comprehensive guide from the basics to the latest trends
We have compiled information about metadata. We hope you will use it to establish a system for consistent metadata management across your organization and realize efficient information utilization!
▼I want to know more about generative AI
⇒ Generative AI | Glossary
▼I want to know more about RAG
⇒ Retrieval Augmented Generation (RAG) | Glossary
How generative AI uses metadata
How generative AI uses metadata varies depending on the mechanism (e.g., RAG or AI agent) and the format of the data, but it is generally used in the data search and response processes.
When searching unstructured data such as PDF documents, the number of documents to be searched tends to be enormous. To find the single document the user is looking for, generative AI must search through this vast search range. For example, if metadata is managed to indicate whether a document is a business manual or a proposal, or whether it is an accounting-related document or a legal document, it will be possible to narrow down the search target and perform searches more efficiently.
When searching for structured data managed in a tabular format, such as in a database, it is useful for constructing queries (SQL) to extract data. By understanding the definitions of tables and columns as metadata, you can select the optimal tables and columns based on the user's needs and retrieve data using the appropriate extraction conditions.
When answering a question, the generative AI uses the metadata to understand what kind of data is being referenced as prerequisite knowledge, allowing it to provide an answer that is appropriate to the context and intent.
What can happen if you don't have enough metadata?
Insufficient metadata increases the risk that the AI generating the data will not be able to find the right information and will produce incorrect answers. Even seemingly small omissions or updates to information can have a major impact on the answer results.
For example, let's say a planning officer asks the chatbot, "Analyze the trends in sales for each customer group over the course of a year," and the following response is returned:
We analyzed sales trends for 2019 based on the sales management database. The analysis results for each customer segment are as follows:
Sales for customer category 1 in 2019 were stable in estimated amounts. Total sales were 990,000 yen, with the largest sales recorded in December. Slight peaks were observed in spring and autumn.
Sales for customers in customer category 2 remained stable throughout 2019. Total sales were 820,000 yen, with the largest sales recorded in November. There was a stable sales trend throughout the year.
Some of you may feel uneasy about this answer. This feeling of discomfort can actually occur when metadata is not properly organized. Let's dig a little deeper into the true nature of this discomfort.
You selected the wrong data source
The planner had intended to analyze the sales results registered in the accounting database, but in this case, they are referencing the sales records in the sales management database. If these sales were not linked and managed separately, even if the name "sales" was the same, the timing of recording, calculation formulas, etc. may be different.
Old data is being retrieved
If the update date and time are not managed as metadata, it becomes difficult to update information once it has been imported, and old data will continue to be used indefinitely. Even if you intend to refer to the latest information, the generating AI will not be able to grasp the update time, which could result in returning incorrect answers.
The code number does not tell you the meaning of the data
The answer includes customer classification codes 1 and 2, but if the coding system is unclear, the generating AI may misinterpret the information, and the user may not understand what it means. If it's just a string of letters or numbers, it's unclear what it represents, and the answer may be way off the mark.
I actually want to see the original data, but I can't find it.
Even if it is simply described as a sales negotiation management database, you may want to see the actual data, such as what data was actually extracted and responded to, and which documents were referenced.If the necessary reference source information is not recorded as metadata, it will be unclear where to go when you want to dig deeper into the reliability of the information.
Important metadata to improve the accuracy of generative AI answers
In order for the generative AI to provide accurate answers, it is important to organize the information linked to the data from multiple perspectives. Here, we will explain some of the most common metadata items.
There are various types of metadata that generative AI can refer to, but basic information such as who manages which data and at what point in time the information is is particularly important. In a search enhancement system like RAG, making effective use of each piece of metadata can reduce unnecessary searches and increase accuracy.

Responsible department/updator: Whose data is it?
If there is metadata that identifies the department and person in charge of owning the data, the reliability of the information can be determined quickly. Also, in order to track the latest updates, it is important to know who is performing the updates in order to get highly accurate answers. By clearly identifying who is responsible, it becomes easier for the generation AI to narrow down the correct data sources to refer to.
For example, if it is clear whether sales data is managed by the sales department or the accounting department, the generative AI can construct an answer in a more accurate context. By storing information about the person in charge and department as metadata, it becomes easier to identify additional contact points for inquiries and track the freshness of the data.
Terminology and coding system: What data is this?
For data that makes extensive use of codes and terms, it is extremely important to retain their definitions as metadata. If the meaning cannot be interpreted from letters and numbers alone, there is a higher risk that the generating AI will give an answer based on a misunderstanding.
For example, product codes and area codes have slightly different definitions, and if they are mistakenly confused with other codes, the analysis results will be distorted. If the generation AI can understand the code explanation, it will be able to correctly judge the context when searching and answering questions, and provide more appropriate information.
Creation date/update date: When is the data?
Date and time metadata is essential to prevent the AI generating answers from referencing outdated information. In particular, in fields where trends and time-dependent differences are large, correctly understanding the creation and update dates will determine the accuracy of the answers.
There are many cases where monthly and yearly changes in sales data and customer information are important. If the generation AI can refer to the creation and update dates, it can select the data closest to the time of the inquiry and respond, reducing errors caused by outdated information.
Location/URL: Where is the data?
Knowing which server, file path, or web page the data is on makes it easier to double-check or obtain additional data later. Even if questions arise about the answers provided by the generated AI, if the location and URL are clear, you can quickly access the original data and cross-check it.
For example, if a link to a document is registered as metadata, the reference can be presented to the user when the AI needs to corroborate its answer. Metadata indicating the location is essential for increasing trust as a basis for final decision-making.
Business/Purpose of collection: What is the data for?
The purpose for which the data is collected will have a significant impact on the answers generated by generative AI. By deriving answers based on the purpose, it is possible to eliminate unnecessary information and narrow down the answers to more accurate content.
For example, the perspectives that need to be emphasized differ depending on whether customer survey data will be used to improve marketing measures or as reference data for product development. By providing metadata that allows the generative AI to understand the business and purpose of collection, it can appropriately select the priority information to include in the responses.
Derivation method/calculation formula: What kind of data is it?
Data created through calculations and aggregation can be properly evaluated by recording the calculation formulas and processes as metadata. If used without knowing the background, the generating AI may misjudge the assumptions behind the calculation results.
For example, if the profit margin calculation formula and master data linkage rules are clearly stated, it will be easier for the generative AI to understand the underlying figures. As a result, it will be able to produce persuasive answers for users, increasing the value of using data.
How to prepare metadata for generative AI
Methods for organizing metadata include data catalogs, system integration, and even automatic generation using AI. It is also effective to choose the most appropriate method based on the scale of your company and the nature of your data, and to combine multiple approaches.
If data is expanded without a management system in place, it may become unmanageable. That's why it's important to clearly define schema design and operational rules, and then create a system for continuously updating metadata.
Managing metadata with a data catalog
A data catalog is a system for centrally managing the overview and attributes of data scattered throughout a company. By collectively registering data descriptions, owner information, file layouts, table definitions, and more, it becomes easy to track who viewed and updated which data, and when.
This allows definition information and documents that were previously scattered to be consolidated, making it possible to grasp the update status at a glance. As a result, the accuracy of the metadata that the generation AI can refer to is improved, which has the advantage of making it easier to find the information that forms the basis of an answer.
Saison Technology's metadata management solution "HULFT DataCatalog"
HULFT DataCatalog automatically collects and catalogs metadata about various data managed in a distributed manner within a company. By visualizing the location and history of data and sharing knowledge about the data, it helps to streamline data exploration and promote understanding of the data's contents.
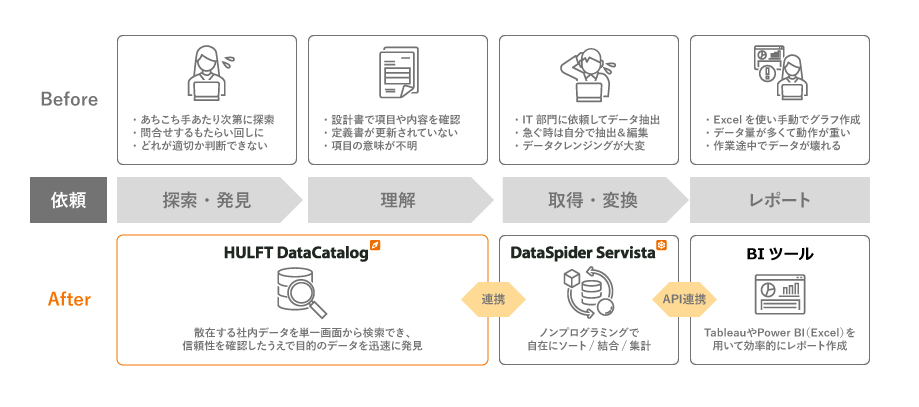
Adding metadata through data integration
In some cases, data sources such as databases, cloud storage, and SaaS store information such as the update date and time, the person who updated, and URLs. In these cases, data integration can automatically retrieve this information as metadata. This has the advantage of significantly reducing the effort required to manually enter metadata, as well as allowing information to be updated in real time.
This type of integration minimizes human input errors and helps maintain timely and accurate information. It is particularly effective in large-scale data operation environments, reducing update costs while maintaining comprehensive metadata.

iPaaS-based data integration platform HULFT Square
HULFT Square is a Japanese iPaaS (cloud-based data integration platform) that supports "data preparation for data utilization" and "data integration that connects business systems." It enables smooth data integration between a wide variety of systems, including various cloud services and on-premise systems.
Automatic metadata generation using AI
In the case of old data held by legacy systems, there may not even be table definition documents or data descriptions. In this case, one approach is to use AI to infer the meaning of tables and columns based on the contents of the data and supplement this as metadata.
Additionally, for text files, images, and audio files, there are methods that can be linked with OCR, image recognition models, or voice recognition models to automatically generate and assign summaries that indicate the type of data, as well as tag information that can be used as classification criteria when searching.Unstructured data in particular is frequently created and updated in the course of everyday work, so it is important to automatically enrich metadata using AI in advance so that it can be referenced by the generation AI.
summary
By preparing metadata, the accuracy of answers and operational efficiency of generative AI will be significantly improved. It can be said that it is not only for accurate searches and data narrowing, but also for underpinning the reliability and persuasiveness of the answers themselves. In today's world where data is constantly increasing, it is important to consider methods for preparing metadata early on and to continue using it.
Once you have a metadata framework in place, you can smoothly add information to new data as it comes in. This will make data utilization with generative AI more powerful and efficient, and you can expect results that directly translate into optimization of customer service and internal operations.
The person who wrote the article
Recommended Content
-

Get an online consultation about data integration
If you would like to hear more about our data utilization platform, we also offer online consultations. -

RAG's data governance realized through iPaaS
We will introduce how using iPaaS can ensure governance in the use of RAG and how it can be used safely and efficiently in business. -

What are the requirements for the data infrastructure required for RAG?
We will focus on "RAG," one approach to generative AI, and explain the key points for developing a data infrastructure that supports the knowledge base required to utilize RAG in business.


