Grasp insights that cannot be grasped through numbers from text and qualitative information! ~ Characteristics of text classification AI ~
AI has a wide range of applications, and is used in all kinds of businesses and services. Recently, text generation AI has been attracting attention, including from the general public. However, unlike numbers, distinguishing, judging, and automatically generating text is a difficult task for AI.
This series introduces AI applications and success stories. In this fourth installment, we spoke with Miyuki Suzuki of Sumitomo Mitsui Trust Bank, a foreign IT vendor who has researched and supported data utilization, from data analysis and utilization to the introduction of machine learning, about AI success stories in textbooks.
▼Profile
Financial Data Utilization Promotion Association, Planning and Publication Committee
Sumitomo Mitsui Trust Bank, Digital Planning Department
Trust Base Inc. Data Science Center
Miyuki Suzuki
*Titles and affiliations are those at the time of interview.
In response to the constraints of the financial industry, our subsidiaries actively introduce new technologies and accumulate know-how
First of all, could you please introduce yourself, Mr. Suzuki?
In his previous two jobs, he worked as a data and AI consultant at foreign IT vendors. He has long supported companies in data utilization, including data integration and accumulation, and proposing and implementing machine learning. Two years ago, he joined Sumitomo Mitsui Trust Bank and Trust Base, where he has been leading the design and implementation of data utilization, or so-called digital transformation, through previous case studies with business users of the Sumitomo Mitsui Trust Group.
What kind of business does Sumitomo Mitsui Trust Bank conduct?
In addition to the banking services you might imagine, such as deposits, loans, and foreign exchange, trust banks also provide services such as corporate pensions, defined contribution pensions, and stock transfer agency services (shareholder management for corporations and shareholder meetings). They also handle inheritance-related matters. Sumitomo Mitsui Trust Bank, in particular, handles a wide range of asset-related services for both individuals and corporations, including real estate asset management and administration, and is highly regarded for its comprehensive strength due to the wide range of services it can handle.
What kind of company is Trust Base, where you also work?
Trust Base is a company that promotes and leads digital transformation for the Sumitomo Mitsui Trust Group, which includes Sumitomo Mitsui Trust Bank. Because trust and credibility are crucial in the banking business, there are many more rules and regulations than in other industries. This often limits the freedom to develop systems and opportunities to try out cutting-edge technologies such as analytical methods. For example, Trust Base is the first to introduce technologies and services that are gaining global attention, such as ChatGPT. Trust Base serves as the information strategy subsidiary within the group, accumulating know-how for incorporating these technologies into banking operations.
This time, we will explain AI processing of documents, a set of documents that are inseparable from banking operations.
It is possible to apply the strengths and weaknesses of qualitative information by incorporating numbers.
I hear that the financial industry is also moving towards a paperless society, such as eliminating seals, but what is the reality?
Although the digitization of documents is progressing, the culture of documents and text remains deeply rooted, as there is still a lot of contract work. However, the digitization of text itself is progressing, and not only standard text such as contracts, but also non-standard text such as customer surveys is being digitized using OCR technology. As long as employees continue to look over this digitized data as in the past, it will not be possible to improve work efficiency or eliminate personal dependency, so hopes are being placed on AI.
The figure below shows the main types of text data generated in the financial industry.

Text classification AI application areas (financial industry)
*An explanatory video is provided at the end of the article.
When analyzing free text, there are two approaches: "unification" and "interpretation." "Unification" involves eliminating variations in characters, as in the "address notation" discussed by Horie in Chapter 3 (link to explanatory article). For example, a human would recognize "Trust Base" and "Trust Base" as referring to the same company name, but when run through AI, they may be recognized as different company names. Therefore, we will unify them as "Trust Base." "Interpretation" uses natural language processing technology to perform summarization, tagging, and other processes to standardize the interpretation of free text, which is subject to personal interpretation.
The following table shows the four main patterns used when classifying free text using AI. As you can see from the table, the type of analysis changes depending on whether there is a single or multiple data source, and whether or not you define the purpose before analyzing.
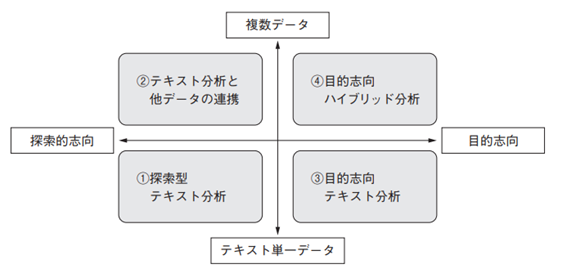
Four patterns of text classification AI
*An explanatory video is provided at the end of the article.
When using text classification AI, the first thing to consider is "Why do I want to use text classification AI?" For example, if you want to automate a task such as a customer survey, where a person reads through each item and extracts information such as "This is what they are interested in," then you should consider exploratory text analysis. In this case, the main objective is to improve work efficiency and eliminate subjective judgment.
Text, for better or worse, has an "ambiguity" about it. While it can provide insights that numbers alone cannot, it's also difficult to say with certainty that "this is what the customer is definitely looking for!" Text analysis, which is on the "multiple data" side of the table above, and goal-driven hybrid analysis, combine text with other data to more clearly identify goals and insights by combining text with customer data and numbers.
For text classification, does the data source have features?
Unlike with numbers, when it comes to text classification, the important things to consider are "who wrote it" and "who the origin is." Free text generated in banking operations includes "customer-origin free text" such as questionnaires filled out directly by customers, "customer-origin voice digitization" generated at customer contact points such as contact centers, and "banker-origin free text" written by bank employees or staff who meet with customers.
Customer-driven free text and digitized voice data are very important data sources in terms of improving customer service.
In what cases is free text from bank employee origin useful?
Examples of documents originating from bank employees include diaries and proposals. Because these are written from the perspective of bank employees and salespeople, it cannot be said that they can extract the customer's thoughts. However, information such as changes in life stages and what the customer was interested in and concerned about can be gleaned from the information gathered through interviews by "experts."
One more point, unique to text classification, is that it is necessary to take into consideration the differences in wording depending on whether the customer is a corporation or an individual. For example, in surveys, individual customers often clearly state that "the service is bad," but corporate customers, perhaps because they are perceived as business partners, often use more indirect wording, such as "the support is good, but I wish they would pay more attention to the service aspect." We will perform text classification while being aware of these differences.

In text classification, the question "Whose perspective is the data from?" is important
How do you process the data source?
First, when conducting an "analysis to improve customer satisfaction," a sentiment analysis is carried out based on the data source mentioned above, "customer-driven free text," or data from a survey written by customers.
Complaints may be predicted and analyzed with the goal of improving customer service. In such cases, the "contact history" written by contact center operators may be used as the data source, but since sentiment analysis of the text written by the operator may extract the operator's emotions, it is necessary to use ingenuity, such as "goal-oriented text analysis," which sets a goal in advance.
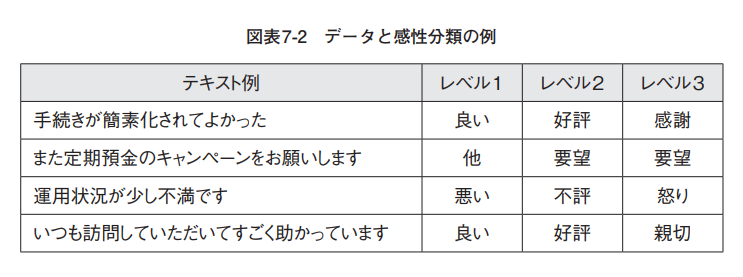
Data and emotion classification examples
*An explanatory video is provided at the end of the article.
The sentiment analysis we use outputs three levels of emotion. Level 1 indicates whether a comment is "good" or "bad." Level 3 further classifies comments into 81 different emotions. At this time, we set it to exclude greetings such as "Thank you as always" and "Thank you for your help," which are not necessary for sentiment analysis.
How about using bank employee origin free text as a data source?
The contact history mentioned above can also be used to perform "sales opportunity creation analysis." In this case, analysis is performed using trends in frequently occurring words and binary classification. Sales opportunities, that is, changes in the customer's life stage and interests, can be extracted and used to create effective proposals. In addition to simply performing analysis using AI, it is also important to collaborate with business users who are promoting sales, such as by reviewing the analysis results.
The analysis results focus on "what business users already know and understand?"
Can you tell me about the validation?
When it comes to text classification, it is especially important to handle known information. When you provide known information, in other words, analysis results, to sales representatives, they may think, "I already know this," or "I understand this." This can lead to them thinking, "Is this all there is to using AI?" and failing to understand the value of it.
Therefore, we place importance on distinguishing between known and new information. In desk-top testing, results that can be assumed to be known are included in order to improve accuracy, but in practical testing, known information is excluded and the results are deployed to business users such as sales representatives, and adjustments are made based on feedback.
Perhaps because text classification analyzes qualitative information, it seems to have a different perspective and approach than other successful AI patterns.
That may be true. There is one more thing I'd like you to pay attention to, which is unique to text classification: "operation." In analyzing customer satisfaction improvement, you can determine whether accuracy has improved by looking at "how many complaints the AI was able to pick up that would have been overlooked by the human eye" and "how many complaints it was able to pick up that were not recognized but needed to be addressed."
In the analysis of sales opportunity creation, it can be determined that accuracy has improved due to an increase in opportunities for sales representatives to make proposals to customers, as well as an increase in cross-selling and up-selling. Because both analyses involve qualitative information, it is a good idea to consider what indicators should be set to improve accuracy and how to implement the PDCA cycle.
Written by Financial Data Utilization Promotion Association
"Success Patterns for Financial AI"
Now on sale and a big hit!
"FDUA Financial Data Utilization Promotion Association Tie-up Project" video
On Saison Technology's official YouTube channel,
We are introducing an explanatory video by Miyuki Suzuki of Sumitomo Mitsui Trust Bank, who wrote Chapter 7.
Please see also.
Related Content
-

Survival Strategy in an AI-driven Society: How will humans live in an artificial super-intelligence society?
-

Applicable AI that can quantitatively judge and evaluate core credit operations of banks - Tips for developing credit screening AI -
-

Making real estate investment more convenient and high-quality. The key is to create a model that is easy for people to interpret - Focus of value calculation AI -