The Importance of a Data Infrastructure to Support Data Utilization: 9 Criteria for Selecting a Data Pipeline


Data preparation and integration are important when building a foundation for data utilization. In particular, the selection of a data pipeline has a significant impact on the efficiency of data utilization. This article explains the importance of a data infrastructure and nine criteria to consider when selecting a pipeline.
Essential element for accelerating data utilization: Establishing a data infrastructure
When working on data utilization, a "data infrastructure" is extremely important because it forms the basis for extracting value from data. A data infrastructure is the technical infrastructure for aggregating, organizing, storing, and analyzing data, and includes data warehouses (DWHs), data lakes, data pipelines (ETL / iPaaS), and analysis tools.
An inadequate data infrastructure increases the risk of information fragmentation and inconsistent data leading to incorrect decision-making. It also reduces the efficiency of analysis, making it difficult to make quick decisions. It also creates security risks and governance issues, which are likely to have a negative impact on business growth.
The development of a data infrastructure is not just a technical element for storing and managing data; it also plays an important role in providing a foundation for companies to strategically utilize data.
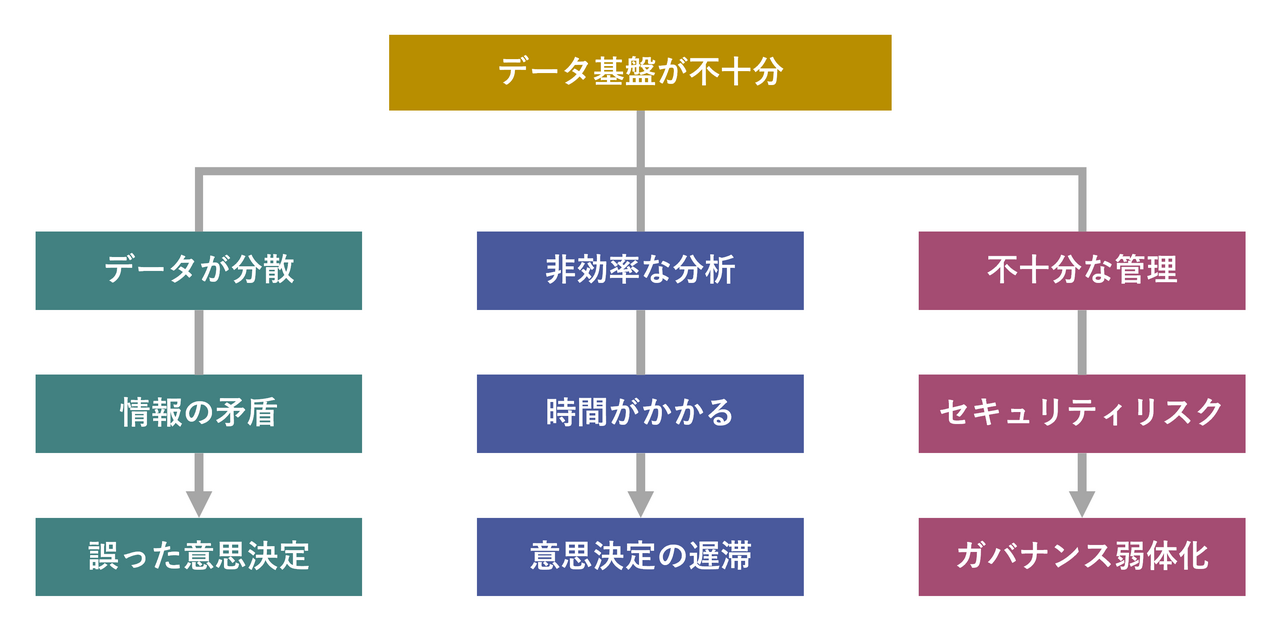
"Data organization and integration" is a challenge in building a data infrastructure
A challenge many companies face when building their data infrastructure is integrating data from different sources.
Within a company, a variety of data is generated from different systems and applications. Maintaining consistency in the data collected from these multiple systems and departments while integrating it into a form that can be used across the entire company is extremely difficult and requires time and resources. For example, when customer data, sales data, inventory data, etc. are stored in different formats, a system is needed to centrally integrate and visualize this data.
The role of data pipelines in data infrastructure
Data pipelines (also known as iPaaS or ETL) play a very important role in data infrastructure.
Companies have a variety of data sources, including different systems and applications, and a data pipeline is essential for centrally managing this data and converting it into a form that is useful for analysis and utilization.

1. Efficient data integration
A data pipeline collects data from different sources (databases, cloud storage, externalAPIs, etc.) and centralizes it. Manual data integration is time-consuming, costly, and prone to human error. Data pipelines automate these processes, making data integration more efficient and accurate.
2. Data preprocessing and transformation
Collected data is often not suitable for analysis as is. Data pipelines cleanse and transform data. This allows for the creation of high-quality datasets by filling in missing values, eliminating duplicates, converting data types, and standardizing data. By centralizing data and preparing it in the required format, data availability is improved across the company.
3. Real-time data integration
In addition to traditional batch processing-type data integration, modern businesses require real-time data integration. Data pipelines collect and process real-time data, enabling immediate reflection of customer behavior, product demand, inventory status, and more, supporting faster decision-making. Real-time data integration allows you to instantly understand the business situation and make faster decisions.
4. Integrating heterogeneous data sources
Integrating data becomes more complex when multiple companies and partners have different systems, data formats, and security requirements. A data pipeline efficiently integrates these different types of data and transforms it into a form that can be used for analysis. A data pipeline ensures that the data you need to get a complete picture of your business is available in a consistent form.
5. Automate data flows
Data pipelines automate the entire process of collecting, transforming, and storing data. This automation reduces manual data integration work and reduces the risk of errors. You can also schedule regular data updates, ensuring your data infrastructure is always up-to-date.
6. Scalability
Even if your business grows and the amount of data increases, you can smoothly scale up by using a data pipeline. If you were to manually integrate data, it would be difficult to keep up with the increasing amount of data, but because the pipeline is automated, it can also handle large amounts of data.
7. Ease of development
Typically, relying on the IT department for data pipeline processes can slow down business progress and result in lost opportunities. Therefore, it is important to select a data pipeline tool that can be used even by non-IT personnel. The ability for business personnel to independently manage data flow is essential for accelerating the speed of problem resolution and flexibly responding to the business environment.
8. Anomaly Detection and Recovery
Data pipelines go through many processing steps to aggregate data and make it ready for analysis, but errors are inevitable along the way. Missing data, outliers, format inconsistencies, and other issues can cause processing to halt midway or result in incorrect data being sent. A flexible error handling mechanism is crucial for quickly identifying problems and stabilizing data pipeline operations.
9. Security and Compliance
Data often contains personal and confidential information, and its handling requires advanced security measures. Inadequate security can lead to unauthorized access to data through cyber attacks or internal fraud, which could seriously damage a company's credibility and brand image. Furthermore, lack of proper compliance management can result in the risk of legal penalties and litigation. With a solid security and compliance system in place, companies can avoid legal risks and increase trust in data usage.
On-premise or cloud: Flexible data pipeline with HULFT Square

iPaaS-based data integration platform HULFT Square
HULFT Square is a Japanese iPaaS (cloud-based data integration platform) that supports "data preparation for data utilization" and "data integration that connects business systems." It enables smooth data integration between a wide variety of systems, including various cloud services and on-premise systems.
9 reasons why we recommend HULFT Square for your data pipeline
HULFT Square can meet the six requirements for a data pipeline, as well as three requirements that lead to development productivity and security.
1. Diversity in Data Integration
A data pipeline must be able to efficiently extract data from a variety of data sources (databases, CSVs, APIs, SaaS tools, etc.).
HULFT Square has a wide range of connectors and has a proven track record of connecting to a variety of protocols, including REST APIs(RESTful APIs) offered by many SaaS providers, as well as JDBC, FTP, IMAP/POP3/SMTP, and supports over 150 data sources both domestically and internationally.
2. Flexible data conversion and processing functions
Your data pipeline should have flexible ETL capabilities that can perform any necessary transformations (such as changing data types or performing aggregations) before the data is loaded into your DWH.
HULFT Square not only provides basic conversion functions such as combining, converting, and aggregating data, but can also flexibly accommodate conversion requirements unique to Japan, such as hiragana/katakana conversion, Japanese/Western calendar conversion, full-width/half-width conversion, and Chinese numeral/alphanumeric conversion.
3. Real-time and batch processing
If you want to reflect data in real time and gain immediate business insights, you need real-time data streaming capabilities, but if you need to process large amounts of data periodically, you should choose a pipeline that is suitable for batch processing.
HULFT Square can execute pipelines triggered by a variety of events, such as scheduled execution, execution via REST API, or execution upon receiving a file.
4. Absorption of differences in data formats
Data pipelines must be flexible enough to effectively process and integrate diverse internal and external data sources, formats, and protocols.
HULFT Square can flexibly integrate with the services and systems you connect to in three different ways. You can choose the optimal connection method depending on the availability of a dedicated connector, the type of API provided by the service you connect to, and your system's network environment.
5. Orchestration
When multiple data processing steps are required, orchestration capabilities are required to manage the data extract, transform, and load (ETL) flow, and when tasks have dependencies, the ability to ensure they occur at the right time is required.
HULFT Square 's extensive control functions, such as conditional branching, loop processing, parallel execution and queue processing, and transaction commit and rollback control, enable detailed data flow management tailored to your requirements.
6. Scalability
As a business grows steadily, the amount of data flowing into the data warehouse increases, and the data pipeline must be scalable (capable of horizontal and vertical scaling) to keep up with the speed of business growth.
HULFT Square can be freely scaled up or out, allowing you to select the appropriate scale depending on the expected amount of data and the required performance indicators.Start smallIt can be used for a wide range of applications, from small-scale to large-scale operations.
7. No-code/low-code support
For users who do not have specialized skills in data integration technology, the no-code functionality that allows them to visually build data flows makes it easier for people in a variety of roles to be involved in data utilization.
With HULFT Square, intuitive drag-and-drop operation allows even user departments to carry out development quickly. Furthermore, comprehensive documentation and detailed guidance from SuccessNavi allow for smooth step-ups and efficient learning.
8. Flexible Error Handling
If a data pipeline encounters an error along the way, it needs to have a retry process, error logging, and notification capabilities.
HULFT Square detects errors and problems that occur during data transfer and processing and handles them appropriately. The type of error, the location where it occurred, and detailed information (such as a stack trace) are recorded in a log, and when an error occurs, a notification is sent to the appropriate person, allowing the problem to be dealt with promptly. The behavior when an error occurs can be freely customized.
9. Data Protection and Privacy Standards
Data transferred through the pipeline must be encrypted, and strong security measures are required, especially when dealing with sensitive data.
HULFT Square complies with GDPR, CCPA, and SOC 2 Type 2, so you can use it with confidence regardless of country or region.

Use Cases
Please take a look at a use case that utilizes HULFT Square as a data pipeline.


For inquiries about HULFT Square, please click here.
The person who wrote the article
Recommended Content
-

A step-by-step guide to building a data infrastructure with Snowflake
We will explain the process of building a data infrastructure using Snowflake in an easy-to-understand manner, focusing on the important points at each step. -

Generative AI for Business Analytics
This webinar will explain practical initiatives using data utilization platforms, with demonstrations. Please also take a look at this. (Viewing time: approximately 20 minutes) -

Get an online consultation about data utilization
If you would like to hear more about our data utilization platform, we also offer online consultations.
Related Content
-

The Use of Generative AI in Talent Management: From Intuition to Data-Driven Approaches
-

What is CDC (Change Data Capture)? – A method for securely and reliably transporting data from on-premises systems.
-
data integration techniques for character code conversion—preparing for a mix of SJIS, JEF, and Unicode.