data integration techniques for character code conversion—preparing for a mix of SJIS, JEF, and Unicode.


When implementing data integration in the field, have you ever encountered character encoding problems such as "Why is this field displaying incorrectly?" or "The numbers don't match even after conversion?" In many cases, these are treated as simple conversion failures and dealt with on an ad-hoc basis. As a result, the same problems recur when integrating with other systems, and the costs of addressing them accumulate. However, this very repetition is actually the fundamental reason why data integration is so difficult.
This article explains the need to re-examine the character encoding problem not as a temporary technical issue, but as a "structural operational challenge."
Character encoding issues are structural operational challenges.
The more data integration progresses, the more character encoding issues surface.
Amidst the push for digital transformation (DX) and data utilization, there is a growing demand to leverage data accumulated in existing systems or to integrate new systems while retaining legacy assets. This inevitably involves data movement across "character encoding boundaries."
Enterprise systems are designed with different character encoding assumptions due to the era in which they were implemented and the platforms on which they were built. Even if a system works fine on its own, each additional connection to another system increases the amount of adjustment work required, such as adding conversion specifications, handling exception characters, verifying overflows, and increasing the number of test cases. This is not a problem with individual technologies, but rather a problem that arises from connecting systems that were built with different assumptions.
What's needed is to link the data while preserving its meaning.
It's often thought that "simply converting the character encoding will solve the problem," but in practice, it's not that simple. For example, problems can arise such as non-existent characters or machine-dependent characters in the target system, characters that look the same but have different meanings, inconsistencies due to normalization, and data corruption due to changes in byte length.
The issue here is not whether the characters can be displayed correctly, but whether the data retains its meaning as business data. What should be protected in data integration is business information, not character codes. In other words, what is required is not code conversion, but ensuring data integrity through semantic conversion. If this is not designed properly and is dealt with using conversion tools or scripts, new inconsistencies will be created with each new integration.
▼I want to know more about data integration.
⇒ data integration / data integration platform | Glossary
It is important to solve the problem structurally, rather than just providing a temporary fix.
There are commonalities in workplaces where character encoding problems repeatedly occur. These include the creation of custom conversions for each collaboration, the confines of the specific person responsible, and the lack of a systematic approach to handling exceptions. When this is repeated, only conversion assets that cannot be reused accumulate.
- Individual conversions are implemented for each integration.
- The specifications are highly dependent on specific individuals.
- Exception handling is not documented.
- The amount of transformable assets that cannot be reused is increasing.
This is not a matter of technical skill, but rather stems from the fact that the operational design is "ad-hoc."
Since data integration will occur continuously, what is needed is not a conversion solution each time, but a structural solution.
Real-world examples of encountering character encoding limitations

Case Study 1: We want to use mainframe assets in an open system.
This is an example of a data migration project that made business data, previously managed on a mainframe, accessible from open systems.
The migration involved approximately 25 different types of data, totaling several million entries. The main problem during this migration was the change in byte length due to the change in character encoding.
On the mainframe, half-width katakana characters are stored as 1 byte, but in the UTF-8 environment of the migration destination, the same character is stored as 3 bytes. As a result, the existing fixed-length record definitions were insufficient, causing field overflows and data corruption. Further investigation revealed that due to accumulated specification changes during operation, data representation differed across generations, with a mix of space-padding and zero-padding, resulting in a discrepancy between the current specifications and the actual data. In other words, a simple code conversion was not sufficient; the data needed to be corrected to match current requirements during the migration. The idea of rebuilding the host-side definitions based on UTF-8 was considered, but this would have had a significant impact on mission-critical system, core system and was not a realistic option.
Case Study 2: We want to build a system using a different coding system.
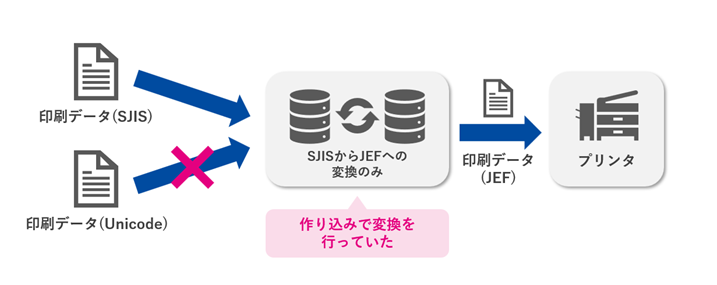
This is an example of an issue that occurred during a collaborative process where print data was output from a business system and then transferred to a printer.
Previously, only the conversion from SJIS to JEF was implemented and operated using separate programs. However, with the increase in Unicode-based data following system updates, the existing system could no longer cope. What was needed now was not a single conversion system, but a mechanism that could convert between the SJIS, Unicode, and JEF code systems.
Furthermore, since the presence of non-standard characters that the printer does not support would result in a printing error, a mechanism was needed to detect these non-standard characters in advance and exclude them as anomalous data.
If we were to handle these issues through individual development as before, the addition and modification of conversion logic would be required for each collaboration specification, dramatically increasing the maintenance burden. In this case, the challenge was not so much the difference in character codes themselves, but rather the operational structure that required continuous adaptation to different character specifications for each output destination.
Case Study 3: We want to operate data integration with minimal effort and cost.
As a result of operating a diverse range of business systems for many years, the number of systems to be integrated has increased to approximately 30, and the number of interfaces to around 500. The number of data records processed per day sometimes exceeds 10 million, making data integration itself a prerequisite for supporting the business. However, because integration processes had been individually optimized and built in with each system implementation,
- A mix of communication methods including FTP, RCP, and file sharing.
- The implementation of delivery confirmation and error handling is inconsistent.
- I cannot grasp the overall picture of the integration specifications.
- Unnecessary and redundant interfaces are proliferating.
This resulted in a fragmentation of operations.
The individually implemented ETL tools were over-specced and difficult to use effectively, requiring time for investigation and modification each time, and the management burden increased with the addition of interfaces, resulting in them becoming increasingly black boxes.
The problem in this case wasn't the difficulty of specific character code conversions. Rather, it was the operational structure itself: as data integration increased, conversions, communications, and exception handling accumulated as individual assets, making it impossible to control the overall system. As a result, inconsistencies caused by character code differences had to be addressed through investigation and modification on a case-by-case basis, leading to persistently high man-hours and costs.
▼I want to know more about ETL
⇒ ETL|Glossary
DataMagic solves character encoding problems.
DataMagic is a data transformation tool for collecting, transforming, and integrating data scattered throughout an enterprise. It supports a wide range of character encodings and data formats, allowing for integration across different systems while preserving data meaning. Its GUI-based development interface eliminates the need for specialized programming, and it offers lower costs and faster processing compared to other ETL tools.

DataMagic, a data processing and conversion tool
Saison Technology's "DataMagic" is a translator that absorbs "data discrepancies" in system integration. It supports a wide range of data formats and character encodings, enabling smooth and complex data conversions.
All three of the cases I just mentioned were resolved by implementing DataMagic.
In Case Study ①, we established a conversion process that adapts the data to the destination specifications while preserving its meaning by simultaneously performing character code conversion and re-editing and rearranging items on a per-item basis.
the result,
- Resolving digit shifts and truncation due to character encoding differences
- Absorption and normalization of data containing mixed specification changes
- Elimination of correction processing that was previously performed by individual programs.
- Improved configuration to accommodate future specification changes.
We have created a highly reproducible data migration platform that does not rely on manual correction work.
In Case Study ②, a conversion flow was constructed that integrated character code conversion and external character detection.
- Supports bidirectional conversion between SJIS and Unicode, SJIS and JEF, and Unicode and JEF.
- Automatically extracts non-printable characters and separates them as abnormal data.
- Reduced maintenance burden by eliminating custom conversions.
- Improved to a more flexible configuration that can accommodate the addition of new character systems.
This has allowed us to standardize pre-printing processes and proactively prevent environment-dependent character encoding problems.
In Case Study 3, we restructured data integration platform to one that can be built without programming, and achieved standardization through centralized interface management.
the result,
- By enabling centralized management of the integration process, the time required for preliminary investigations and impact analyses has been significantly reduced.
- It becomes easier to add new interfaces and respond to specification changes, reducing development time by more than 50%.
- This will enable operations that do not rely on specialized technical skills, and will allow for a transition to a system that promotes in-house development.
- By deploying a standardized platform across different platforms, it becomes possible to expand the scope of data integration.
Currently, as we migrate from the old infrastructure, we are already seeing improvements in development efficiency and reduced operational burden, and we are looking ahead to further expanding its application areas.
Finally
The cases discussed in this paper were not simply character encoding conversion problems, but rather "structural data integration challenges" that arose from continuously connecting systems designed under different assumptions.
Traditionally, we've had to create custom conversion and correction processes for each integration, absorbing problems with ad-hoc solutions. However, with this method, the adjustment burden accumulates as the number of systems increases, and the same problems recur in different forms.
The key is not to address the differences between individual character encodings, but to design a system that allows data to be shared while maintaining its meaning and consistency. By standardizing conversions as a "reusable sharing process" rather than treating them as a "task," sustainable data integration that transcends character encoding barriers can finally be achieved.
Using DataMagic is merely one concrete implementation method for achieving this goal. The real challenge lies in moving away from individually optimized transformations and shifting to an operational structure based on collaboration.
In the future, there will be an increasing number of situations where we need to connect new systems while leveraging existing assets. What will be required then is not simply a collection of conversion technologies, but a perspective that designs and manages data integration in a sustainable manner. We hope this article will help to reconsider the challenges caused by differences in character encoding not as temporary technical problems, but as design challenges for the entire operation.

Saison Technology Online Consultation
If you would like to hear more about our data utilization platform, we also offer online consultations. Please feel free to contact us!
The person who wrote the article
Recommended Content
-

"DataMagic" is recommended for its "fast, cheap, and easy" features.
This is a list of articles where you can find detailed information about DataMagic features. It can also be used as a manual. -

What is data utilization? Basic knowledge to increase business value
We will explain the key points for increasing business value by organizing the basic concepts, benefits, approaches, and main challenges of data utilization. -

Download trial version
DataMagic is also available as an evaluation version. If you're curious about its usability, please follow the instructions to download and try it out.


