Moving beyond PoC! What is the "data pipeline" that supports RAG's production operations?

Retrieval-Augmented Generation (RAG), which supports a system in which generative AI answers based on specific information sources such as internal data, is attracting attention as a key to promoting data utilization in business. However, the current situation is that the adoption of RAG in many companies stops at the PoC stage. The key to breaking this situation is a "data pipeline" that supplies high-quality data to generative AI.
In this column, we will explain the construction of a data pipeline that supports RAG's production operations and the role of iPaaS in helping to achieve this.
Why doesn't RAG go beyond PoC?
There are common issues that prevent RAG implementation projects from moving from the PoC stage to full-scale operation. While many companies are conducting RAG proof-of-concept experiments, the reasons for their lack of progress toward full-scale operation lie not only in technical aspects, but also in operational and data management issues. While a PoC uses a limited data set, it is easy to verify the accuracy of responses, and unexpected problems frequently arise in a production environment that handles large amounts of unstructured data. Furthermore, factors that are often overlooked in a PoC, such as legal compliance and business requirements, must be addressed during the operation phase.
▼I want to know more about RAG
⇒ Retrieval Augmented Generation (RAG) | Glossary
The accuracy of the answers is not improved
The data referenced by RAG consists largely of unstructured data in a variety of formats, including PDFs, web pages, and audio data. While humans can understand this data, the LLM that powers RAG is not adept at properly grasping the context from these formats. For example, tables, images, and complex layouts within documents can hinder LLM analysis. As a result, LLM is unable to accurately extract important information, making the accuracy of RAG's answers highly unstable.
Unstructured data often contains redundant information that is not intended to be meaningful, or unnecessary noise that interferes with analysis. For example, text extracted from a web page may contain advertisements, navigation links, or other elements that are unnecessary for the generative AI's answers. This noise makes it difficult for LLM to accurately identify and extract the information that is truly needed and properly understand the context. As a result, RAG is confused by the noise, and there is a risk that it will not achieve the expected accuracy of answers and may even generate incorrect information.
▼I want to know more about LLM
⇒ Large Language Model (LLM) | Glossary
I can't substantiate the answer
Because the answers generated by generative AI are used in business settings, their accuracy must be guaranteed. To achieve this, transparency, which clearly indicates the source of the answer, is essential. However, in RAG implementations at the PoC stage, there are many cases where reference source information is lacking or the design makes it difficult to track. For example, if the page number, URL, or specific author information of the document on which the answer is based is not linked, it becomes difficult for users and operators to quickly verify the basis of the answer.
Under these circumstances, there is a high risk of incorrect answers due to "hallucination," in which the generative AI generates information that is not based on facts, or inaccurate content due to reference errors being provided to users. This not only damages the company's credibility, but could even lead to decisions being made based on incorrect information. In production operations, "metadata management," which makes it easy to link data sources with the information referenced by the RAG, is an extremely important element in increasing the transparency and reliability of information regarding RAG's answers. This makes it possible to immediately verify and correct suspicious answers.
Duplicate management of data occurs
When implementing RAG, it is common to extract data from existing systems, copy it, and store it as a search index dedicated to RAG. However, this approach leads to "dual management" of the original data and the RAG data, making maintaining data consistency extremely complicated. When dealing with frequently updated data such as customer information, product catalogs, and internal regulations, the RAG data must be constantly synchronized with the original data, which creates a maintenance burden that is impractical to do manually. Without automation, there is a constant risk of data inconsistency.
Furthermore, dual data management creates many operational and management challenges. For example, it makes centralized management of access rights difficult and audit trail management complicated. This is undesirable from the perspective of security risks and data governance. Version management also tends to become cumbersome. Even if the latest information can be provided to RAG, if these operational costs increase, cost-effectiveness will decrease and it will be difficult to sustain long-term system operation. Eliminating dual management is essential for efficient and sustainable operation.
Unable to detect data anomalies
During the PoC stage of RAG, the amount of data handled is limited, so even if there is a problem with data ingestion, it is relatively easy to notice. However, in production operation, a huge amount of data flows in from multiple sources, making it nearly impossible for a human to visually determine whether the data is correct or not. Even if data ingestion fails or some data is missing, RAG may continue to operate and appear to be providing information without any problems.
If the RAG continues to operate without the operator noticing an anomaly, the accuracy of responses will unknowingly decrease, increasing the risk of providing incorrect information. This could lead to serious business losses and missed opportunities. In particular, if the RAG continues to generate responses while important data is missing, it could even lead to errors in important organizational decision-making. To prevent such situations and maintain the stable operation and reliability of the RAG, it is essential to have a system that monitors the data intake status in real time, automatically detects anomalies, and notifies the operator.
What is the data pipeline for running RAG in production?
In order to resolve the issues facing RAG and move into full-scale operation, it is essential to build a "data pipeline." A data pipeline is a mechanism for efficiently and systematically managing the entire process of data collection, conversion, storage, and send to generative AI. By using this as the foundation of RAG, it is possible to integrate diverse data scattered across different systems, maintain its quality, and keep RAG's datasets up to date.
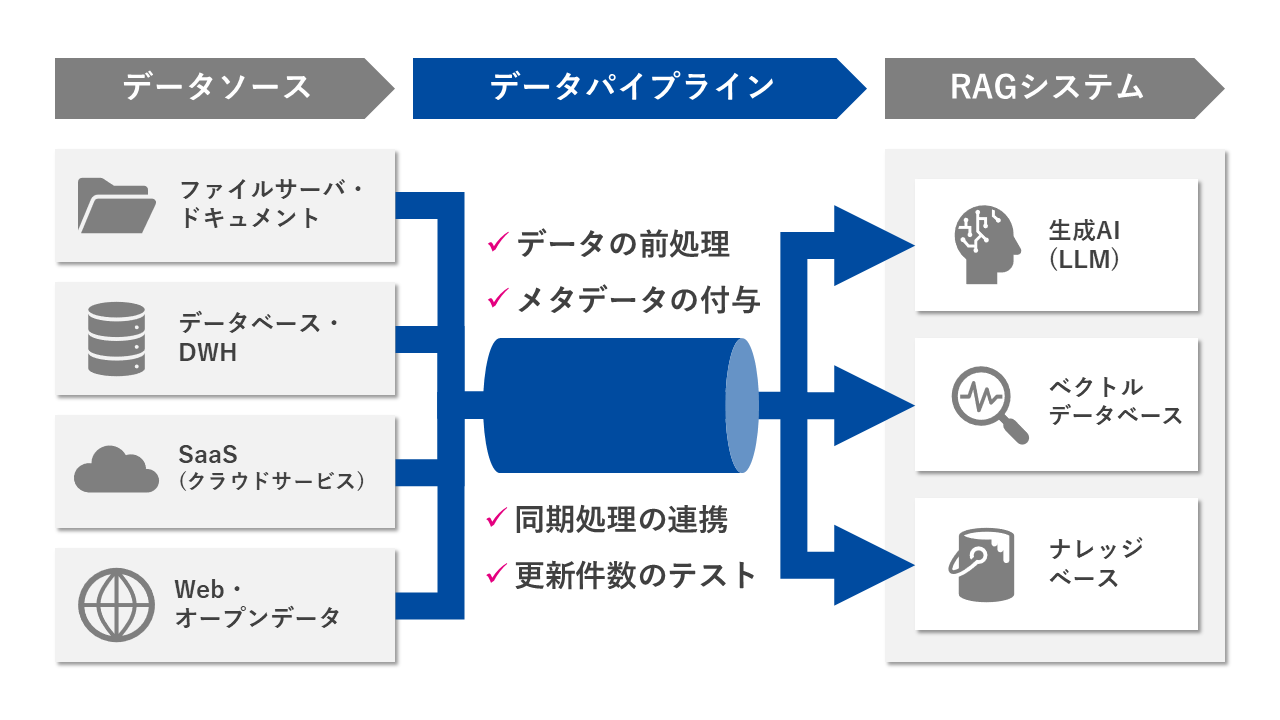
Data Preprocessing
One of the most important steps in RAG operation is "data preprocessing," which involves formatting and processing raw data, which exists in a wide variety of formats, into a form that is easy for LLM to read and understand. Generative AI excels at understanding context and document structure, but its performance is unstable when data is in a disjointed state, such as PDF image data or unorganized text files. This preprocessing step analyzes complex document formats and standardizes them into a hierarchical format with a clear heading structure, allowing LLM to extract information efficiently and improve response accuracy.
Depending on specific business requirements, more advanced preprocessing, such as extracting information from documents and intentionally converting it into a Q&A pair format, can also be effective. This helps RAG generate more direct and accurate answers to specific questions. Automating this data preprocessing process and incorporating it into the data pipeline workflow significantly reduces the manual workload in production operations. At the same time, continuously supplying high-quality data to RAG is key to stabilizing answer accuracy.
Adding metadata
To ensure the reliability of answers generated by RAG and allow users to use the system with confidence, transparency, which clearly indicates the source of the information, is essential. This transparency is achieved by adding metadata to the data itself. For example, by incorporating information such as the document author, last update date and time, scope of access, original system name, access URL, and related keywords into RAG datasets as annotations, it becomes possible to easily present the underlying information to users along with the generated answers.
By assigning this metadata, users can verify the authenticity of the information referenced by RAG for themselves, improving the reliability of the entire RAG system. Furthermore, in the unlikely event that an incorrect answer occurs due to hallucination or other reasons, the original information can be quickly identified through the metadata, enabling a system to be put in place for a swift correction. Metadata must be managed and updated appropriately according to the freshness of the data. Therefore, it is extremely important to carefully consider methods for collecting, assigning, and continuously managing metadata during the data pipeline design phase and incorporate this into the operational process.
Synchronization process coordination
When running a RAG in production, manually rebuilding the RAG search index every time reference data is updated is unrealistic from the standpoint of efficiency and scalability. This is particularly true in a production environment where data volume increases and update frequency increases, making manual operations impossible to keep up with. Therefore, what is crucial is a "synchronization processing integration" mechanism that detects data updates between the data source system and RAG and executes the associated series of processes semi-automatically or fully automatically. This can significantly reduce operational workloads.
This synchronization process is triggered by events such as updating a record in an internal database or adding a new document to a file server, and automatically executes a series of processes in one go, including data preprocessing, adding metadata, and importing it into RAG's search index (vector database, etc.). This allows RAG to always provide answers based on the latest data, maintaining the freshness and accuracy of information.
Testing the number of updates
In the data pipelineteethIt is essential to have a "data quality testing" system that not only imports data but also continuously verifies whether the expected number and content of data is reflected in RAG. In a system like RAG, various issues can occur during the data import process, such as network failures, API errors, inconsistent data formats, or processing interruptions, which can prevent data from being reflected correctly. These issues can quickly affect the quality of RAG's responses and degrade the user experience.
If such data import anomalies are left unchecked, the accuracy of RAG's responses will gradually decline, and in the worst case, it may be unable to answer some questions at all. Therefore, it is important to automatically run tests to check whether the number of records in the updated data source matches the number of data indexed in RAG, or whether there are any anomalies in the content of specific fields. When discrepancies or anomalies are detected, we will create a system that immediately notifies operators via automatic alert functions such as Slack notifications, emails, and dashboard displays. This will allow us to quickly identify the cause of any problems and take action, maintaining the stable quality of RAG's responses.
What is iPaaS that enables data pipelines?
From here, we will explain the role and benefits of iPaaS, a solution that allows you to build a data pipeline for RAG in a way that is easy to use not only for developers but also for business departments and operations personnel.
iPaaS (Integration Platform as a Service) is a cloud-based integration platform that makes it easy to connect and integrate diverse applications and data sources. Using iPaaS, the complex data pipelines required by RAG can be efficiently built and operated. The process of extracting data from a wide range of systems, including file storage, SaaS, and databases, and formatting it into the optimal format for RAG can be achieved with no or low code.
▼I want to know more about iPaaS
⇒ iPaaS | Glossary
This allows data integration and transformation logic to be implemented without specialized knowledge, and operations personnel can modify and monitor workflows themselves. This reduces the burden on development departments and enables quick responses to business demands, enhancing the competitive advantage of using generative AI, including RAG.
Finally
While the focus in PoC tends to be on verifying functionality, processes such as ensuring data quality, management, and updates pose major obstacles to full-scale operation. By carefully designing and operating a data pipeline, data quality can be ensured in all aspects of RAG, including preprocessing of unstructured data, adding metadata, synchronizing updates, and quality monitoring.
Using a platform like iPaaS, complex data integration integration processes can be smoothly designed and implemented, reducing development time and costs while enabling efficient RAG operations across teams, including business departments.
The person who wrote the article
Recommended Content
-

9 criteria for selecting a data pipeline
We'll explain nine criteria to consider when selecting a data pipeline to centrally manage your data and transform it into a form that's useful for analysis and use. -

RAG's data governance realized through iPaaS
We will introduce how using iPaaS can ensure governance in the use of RAG and how it can be used safely and efficiently in business. -

What are the requirements for the data infrastructure required for RAG?
We will focus on "RAG," one approach to generative AI, and introduce the key points for developing a data infrastructure that supports the knowledge base required to utilize RAG in business.
Related Content
-

The Use of Generative AI in Talent Management: From Intuition to Data-Driven Approaches
-

What is CDC (Change Data Capture)? – A method for securely and reliably transporting data from on-premises systems.
-
data integration techniques for character code conversion—preparing for a mix of SJIS, JEF, and Unicode.