文字コード変換を実現するデータ連携術―SJIS・JEF・Unicodeの混在に備える


現場でデータ連携を進める際、「なぜかこの項目だけ文字化けする」「変換したのに桁が合わない」といった文字コード問題に直面した経験はないでしょうか。多くの場合それは単なる変換作業の失敗として個別対応され、場当たり的な修正で収束させられてしまいます。結果として、同じ問題が別システム連携時に再発し、対応コストが積み上がっていく…。しかし、実はこの繰り返しこそが、データ連携を難しくしている本質的な要因です。
本稿では、文字コード問題を一時的な技術課題ではなく、「構造的な運用課題」として捉え直す必要性について解説します。
文字コード問題は構造的な運用課題
データ連携を進めるほど、文字コード問題が表面化する
DX推進やデータ活用の流れの中で、既存システムに蓄積されたデータを活用したい、あるいはレガシー資産を残したまま新しい仕組みと連携したいという要望が増えています。このとき必ず発生するのが、「文字コードの境界」をまたぐデータ移動です。
企業システムは、導入された時代やプラットフォームの違いにより、それぞれ異なる文字コードを前提として設計されています。システム単体では問題なく動作していても、連携対象が1つ増えるごとに、変換仕様の追加や例外文字対応、桁あふれの検証、テストケースの増大といった調整作業が連携のたびに増えていきます。これは個別の技術の問題ではなく、異なる前提で作られたシステム同士を接続していることに起因する問題です。
必要なのはデータの意味を保ったまま連携すること
「文字コードを変換すれば済む」と考えられがちですが、実務ではそれほど単純ではありません。例えば、変換先に存在しない外字や機種依存文字、同一に見えて意味が異なる文字、正規化による不一致、バイト長の変化による項目崩れなどが起こり得ます。
ここで問題になるのは、「文字を正しく表示できるか」ではなく、「業務データとして意味を保持できているか」という点です。データ連携で本来守るべき対象は、文字コードではなく業務情報です。つまり求められるのは、符号変換ではなく、意味変換を伴うデータ整合性の確保です。ここを設計せずに変換ツールやスクリプトで対処すると、連携が増えるたびに新たな不整合を生み出します。
▼データ連携 についてもっと詳しく知りたい
⇒ データ連携 / データ連携基盤 |用語集
その場限りの対応ではなく、構造的に解決することが重要
文字コード問題が繰り返し発生する現場には共通点があります。それは連携のたびに個別変換を作りこみ、その仕様は担当者の中に閉じ、例外処理は体系化されていないという点です。これが繰り返されると、再利用できない変換資産だけが蓄積していきます。
- 連携ごとに個別変換を実装している
- 仕様が属人化している
- 例外処理がドキュメント化されていない
- 再利用できない変換資産が増えている
これは技術力の問題ではなく、運用設計が「都度対応型」になっていることに起因します。
データ連携が継続的に発生する以上、必要なのはその都度の変換対応ではなく、構造としての解決策です。
文字コードの壁にぶつかった実際の事例

事例① メインフレーム資産をオープン系で使いたい
メインフレームで運用してきた業務データを、オープン系システムから利用できるようにするデータ移行を実施した際の事例です。
移行対象は約25種類、総件数は数百万件にのぼりました。この移行で問題となったのが、文字コード変更に伴うバイト長の変化でした。
メインフレームでは半角カタカナを1バイトで格納していますが、移行先のUTF-8では同じ文字が3バイトになります。その結果、既存の固定長レコード定義に収まらず、フィールドオーバーフローが発生し、データ破損につながりました。さらに調査を進めると、運用の過程で仕様変更が積み重なり、スペース埋めとゼロ埋めが混在するなど、世代によってデータ表現が異なり、現行仕様と実データが一致していない状態が明らかになりました。つまり、単純なコード変換では済まず、現行要件に合わせてデータを補正しながら移行する必要があったのです。ホスト側の定義をUTF-8前提に作り直す案も検討されましたが、基幹システムへの影響が大きく、現実的な選択肢ではありませんでした。
事例② 異なるコード体系でシステムを構築したい
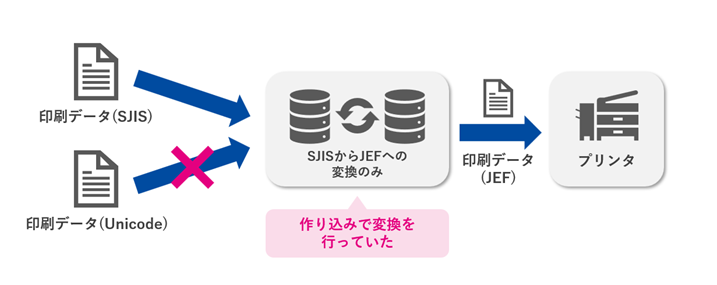
印刷データを業務システムから出力し、プリンタへ受け渡す連携処理において発生した事例です。
従来は、SJISからJEFへの変換のみを個別プログラムで実装して運用していました。しかし、システム更新に伴いUnicodeベースのデータが増えたことで、既存の仕組みでは対応できない状況が生じました。新たに求められたのは、単一の変換ではなく、SJIS・Unicode・JEFの各コード体系を相互に変換できる仕組みでした。
さらに、プリンタが対応していない外字が混在すると印刷エラーになるため、外字を事前に検出し、異常データとして除外する仕組みも必要でした。
これらを従来どおり個別開発で対応しようとすると、変換ロジックの追加・改修が連携仕様ごとに発生し、保守負荷が急増します。このケースでは、文字コードの違いそのものよりも、出力先ごとに異なる文字仕様へ適合させ続けなければならない運用構造が課題となっていました。
事例③ 少ない工数とコストでデータ連携を運用したい
多様な業務システムを長年運用してきた結果、連携対象システムは約30、インターフェースはおよそ500にまで増加。1日に処理するデータ件数は1,000万件を超えることもあり、データ連携そのものがビジネスを支える前提となっていました。しかし、システム導入のたびに個別最適で連携処理を作り込んできたため、
- FTP、RCP、ファイル共有などの通信手段が混在
- 送達確認やエラーハンドリングの実装がバラバラ
- 連携仕様の全体像を把握できない
- 不要・重複したインターフェースが増殖
といった運用の分断が発生していました。
個別導入されたETLツールはオーバースペックで使いこなせず、調査や改修のたびに時間を要し、インターフェース追加とともに管理負荷が増大し、結果としてブラックボックス化が進んでいました。
このケースで問題だったのは、特定の文字コード変換の難しさではありません。データ連携が増えるほど、変換・通信・例外処理が個別資産として蓄積し、全体を統制できなくなる運用構造そのものでした。その結果、文字コードの違いに起因する不整合も、都度調査・都度改修で対応せざるを得ず、工数とコストが高止まりする状態が続いていました。
▼ETLについてもっと詳しく知りたい
⇒ ETL|用語集
文字コード問題を解決するDataMagic
DataMagicは、企業内に分散するデータを収集・変換・連携するためのデータ変換ツールです。幅広い文字コードや各種データ形式に対応し、異なるシステム間でもデータの意味を保ったまま統合できます。GUIによる設定中心で開発できるため専門的なプログラミングを必要とせず、他社ETLツールと比較して低価格かつ高速に処理を実現できる点も特長です。

セゾンテクノロジーが提供する「DataMagic」はシステム連携における「データ差異」を吸収するトランスレーターです。多様なデータ形式や文字コードに対応し、複雑なデータ変換をスムーズに実現します。
先ほど紹介した三つの事例は、すべてDataMagicの導入によって解決されました。
事例①では、文字コード変換と同時に項目単位での再編集・再配置を行うことで、データの意味を保持したまま移行先仕様に適合させる変換プロセスを確立しました。
その結果、
- 文字コード差異による桁ずれ・切り捨ての解消
- 仕様変更が混在したデータの吸収・正規化
- 個別プログラムで行っていた補正処理の撤廃
- 将来の仕様変更にも追従可能な構成へ改善
属人的な補正作業に依存しない、再現性の高いデータ移行基盤を実現しました。
事例②では、文字コード変換と外字検出を一体化した変換フローを構築し、
- SJIS⇔Unicode、SJIS⇔JEF、Unicode⇔JEFの双方向変換に対応
- プリンタ非対応外字を自動抽出し、異常データとして分離
- 作り込み変換の廃止による保守負荷の削減
- 新たな文字体系追加にも対応可能な柔軟な構成へ改善
これにより、印刷前処理を標準化し、環境依存の文字トラブルを未然に防止できるようになりました。
事例③では、ノンプログラミングで構築可能なデータ連携基盤へ再構成し、インターフェースの集中管理による標準化を実現しました。
その結果、
- 連携処理を一元管理できるようになり、事前調査・影響分析の時間を大幅に短縮
- 新規インターフェース追加や仕様変更への対応が容易になり、開発工数を50%以上削減
- 専門技術に依存しない運用が可能となり、内製化を推進できる体制へ移行
- 標準化された基盤を横展開することで、データ連携の適用範囲拡大が可能に
現在は旧基盤からの移行を進めながら、開発効率向上と運用負荷軽減の効果が既に現れており、継続的な活用領域の拡大を見据えています。
さいごに
本稿で取り上げた事例はいずれも、単なる文字コード変換の問題ではなく、異なる前提で設計されたシステム同士を接続し続けてきたことによって生じた「構造的なデータ連携課題」でした。
従来は、連携のたびに個別変換や補正処理を作り込み、その場限りの対応で問題を吸収してきました。しかしこの方法では、システムが増えるほど調整負荷が累積し、同じ問題が形を変えて繰り返されます。
重要なのは、個々の文字コードの違いに対処することではなく、データの意味と整合性を保ったまま連携できる仕組みを前提として設計することです。変換を「作業」として扱うのではなく、「再利用可能な連携プロセス」として標準化することで、はじめて文字コードの壁を越えた持続的なデータ連携が実現できます。
DataMagicの活用は、そのための具体的な実装手段の一つに過ぎません。本質は、個別最適の変換対応から脱却し、連携を前提とした運用構造へ転換できるかどうかにあります。
今後、既存資産を活かしながら新しいシステムと接続していく場面はさらに増えていきます。そのとき求められるのは、変換技術の積み重ねではなく、データ連携を持続可能な形で設計・管理する視点です。本稿が、文字コードの違いに起因する課題を一時的な技術問題としてではなく、運用全体の設計課題として捉え直す一助となれば幸いです。

記事を書いた人





