Developer Blog Series Vol. 12 - Data Visualization and Analysis


Vol.12Single Source of Truth
This is the 12th article on data analysis and visualization.
In this series, I will write down explanations I have given to customers or within my department in the past, and I will also write about hot topics that are currently trending around me.This time, I will be writing about the latter topic.
Using the keyword Single Source of Truth (SSOT), the first half of this article will hopefully be of some use to you, while the second half will be more of a personal hobby.
What is Single Source of Truth (SSOT)?
Single Source of Truth (SSOT) means "the only reliable source of information."
The explanation on Wikipedia is a bit complicated, but roughly speaking it is "a way of thinking that allows everyone in an organization to make decisions based on the same data."
In modern enterprise architecture, this role is primarily played by DWH.
By aggregating data from each system into a DWH and creating dashboards and other data from it, SSOT can effectively be achieved.
*Strictly speaking, this is the definition of SVOT (Single Version of Truth), but I feel that this strictness is not really necessary in the field.
I wrote "by creating dashboards, etc.", but this is not limited to dashboards, machine learning, etc.
Expanding the scope of DWH as SSOT
In the previous article, we touched on Reverse ETL.
SoI (System of Insight) creates business value only when it feeds insights back into SoE (System of Engagement).
The gist of it is that the concept of Reverse ETL exists for this purpose.
This can be illustrated as follows. The part indicated by the blue line is the key point.
Previously, downstream of the DWH, the only thing that mattered was data utilization, but now the arrow extends to SoE as well.
In other words, a DWH can be an SSOT from an SoE perspective.
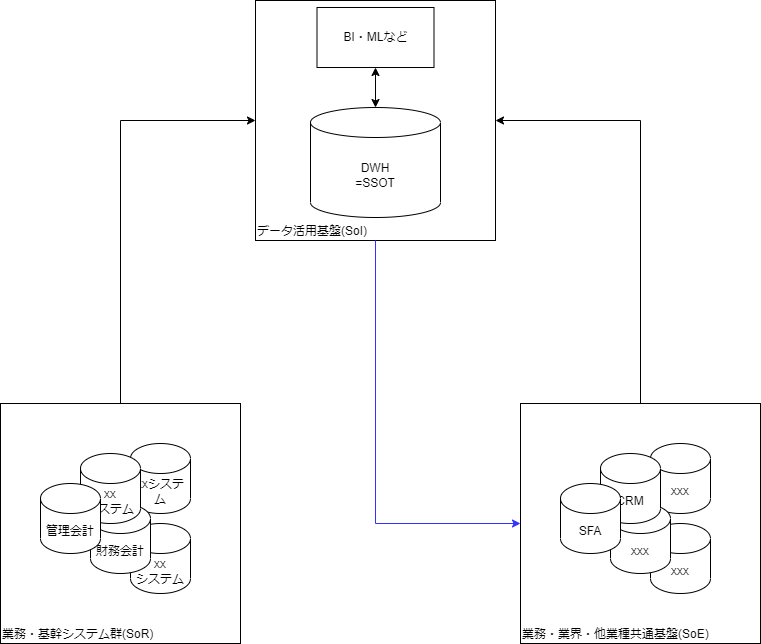
Mapping with the Susanoo Framework
In this article, we introduced the Susanoo Framework from the IPA's DX Practical Guide.
The Susanoo Framework represents the set of technical elements that realize IT systems in a company, and summarizes the technical elements that have been proven effective through research into previous cases.
If we map the elements that can be read from this onto the diagram above, it looks like this:
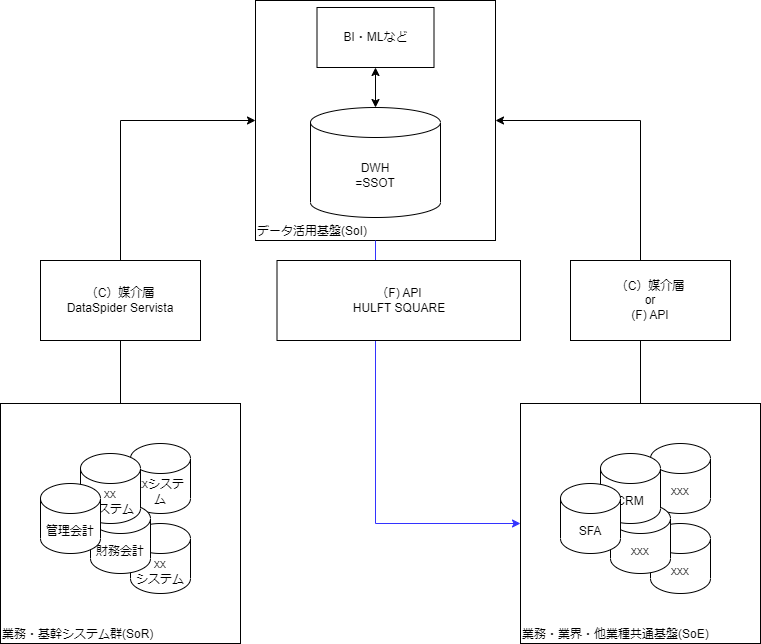
When thinking about what are the benefits of this structure, the following two points immediately come to mind:
- Even if you introduce a new SaaS, you can immediately use the DWH as an SSOT.
- Even if business and mission-critical system, core system are revamped, the impact on those using the data can be minimized by using the DWH as an SSOT.
This is abstracted
A system suitable for implementing DX is one that can independently, agilely, and safely update applications/programs in response to individual changes in business models and services.
via Information-technology Promotion Agency, "DX Practical Guidebook IT System Construction Edition Completed Version 1.0"
This leads to the expression,
The motivation for writing this article is a discussion I had a while ago about how it is important to promote HULFT Square and DI services to customers within this context.
From here on, the content will be more of a hobby, as it will mainly be my impressions when a Databricks engineer introduced me to a certain feature.
The changing situation surrounding SSOT
As we have explained so far, DWH has long been at the heart of SSOT.
However, in recent years, there has been a movement to place a different component at the center.
That's Data Catalog.
Among them, Databricks' Unity Catalog is leading the way in terms of completeness.
Databricks' Unity Catalog recently added a feature called Lakehouse Federation.
Databricks originally had a core technology called Delta Table that enables Datalake to function as a DWH.
Roughly speaking, Lakehouse Federation is a feature that allows Unity Catalog to relay access not only to this Delta Table, but also to MySQL, Azure SQL Database, Snowflake, and other databases.
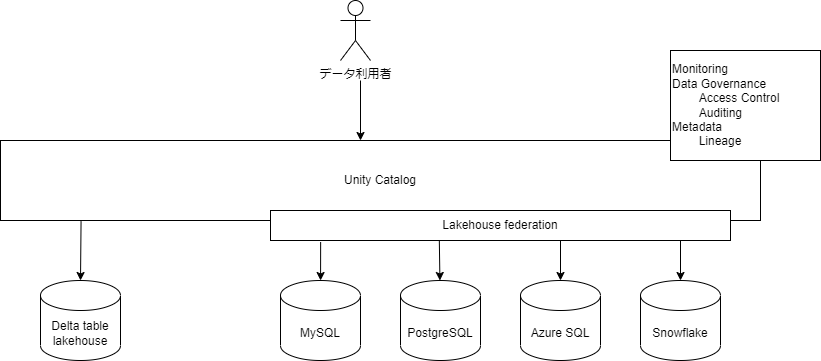
This relay has a number of advantages.
- ① When you issue a query to Unity Catalog, it will convert it to match the DBMS you are connecting to.
- ②Access to each DMBS according to its permissions can be centrally controlled through UnityCatalog.
- ③Since each DBMS is accessed through Unity Catalog, lineage can also be tracked.
Taken together, these benefits mean that there is no need to copy data from each DBMS to the DWH.
Each DBMS is virtually integrated as is through Lakehouse Federation, and even if there are any updates, they can be replaced on the Catalog side.
This means that the Unity Catalog will act as the SSOT.
(However, this is only possible if you fully understand and design it accordingly, which is a difficult assumption.)
Which is better? (personal opinion)
The aforementioned benefit ① is said to be realized based on Databricks' query pushdown mechanism.
Pushdown is implemented in some ETL products, and (in the case of ETL) it is a mechanism whereby the logic written in the ETL pipeline is converted into SQL and executed by resources on the DBMS side.
This mechanism has the advantage that when processing is more efficient on the DBMS side, it can be done there.
However, if that is all you need, you can achieve this by simply writing native DBMS queries in the ETL or defining VIEWs.
The biggest difference between them is that it allows you to integrate Transform logic into ETL, both for people and systems.
For humans, it's obvious. You can see the logic without looking everywhere, just by looking at the ETL pipeline.
By "for the system," I mean lineage. VIEW and other methods fragment lineage information.
Another difference is that you can switch between using DBMS and ETL computing resources simply by enabling or disabling pushdown.
The decision of which method to use for processing is an important turning point.
When comparing Unity Catalog and DWH, there are clear differences in terms of which one is used for processing.
With Unity Catalog, up to a certain point processing must be done on the DBMS side, which is the source of the data.
The DBMS that is the source of data also includes mission-critical system, core system, so I think this is a bit...
On the other hand, once DHW ingests data, it uses the resources of the DWH, so it does not put a load on the source DBMS.
So at this point, I think the traditional method of using a DWH as an SSOT has an advantage.
I wrote about the disadvantages of not moving (copying) data in an article I wrote a while ago.
Conclusion
So, I wrote different content in the first and second halves, just using the same keywords.
Each article is long, but I have sprinkled in keywords that I want you to remember, so I hope that at least one of them will catch your attention.
Thank you for reading to the end.
The person who wrote the article


