Humans and AI team up to learn the process from how to think about data to how to use it - Building targeting AI patterns
In 2015, "deep learning" attracted a lot of attention. This technology was first proposed in 2006 and continued to be developed, and began to emerge in the 2010s. It dramatically accelerated AI development by enabling AI to extract, compare, and analyze features that previously required human intervention. AI continues to evolve day by day and can now perform everyday tasks such as creating illustrations and generating text, but it has also long been attracting attention in the business world.
The banking and financial industries, in particular, have been focusing on the use of AI from an early stage due to the high security requirements and the enormous costs involved in operating branches and other facilities. Each bank and company has been racking their brains and trying different things to determine which operations and fields AI can be introduced and utilized in. This time, we asked Yuki Nabekura, who is in charge of big data in the President's Office at SBI Holdings, Inc. and wrote the second chapter of the book "Financial AI Success Patterns," published in February 2023, to explain the AI success patterns in the financial industry.
▼Profile
Financial Data Utilization Promotion Association, Planning and Publication Committee
SBI Holdings, Inc. President's Office, Big Data
Yuki Nabekura
*Titles and affiliations are those at the time of interview.
Yuki Nabekura, a member of the AI specialist team organized by a leading financial company
First, could you tell us about SBI Holdings, the company you work for?
Founded in 1999 as SoftBank Investment, a subsidiary of SoftBank, with the aim of engaging in venture capital business, the company changed its name to the current SBI Holdings in 2005. It has continued to grow primarily through financial services, including online securities, banking, and insurance, and from the fiscal year ending March 2023, it will restructure its business into five segments: financial services, investment, asset management, cryptocurrency, and non-financial. In order to achieve its goal of "going beyond finance with finance at its core," the company is focusing on improving products and services using advanced technology and creating new businesses, as well as working closely with regional financial institutions to contribute to regional revitalization efforts.
Mr. Nabekura, what kind of work are you involved in at SBI Holdings?
After majoring in space radiation physics at university, he joined SBI Holdings as a new graduate in 2017. As a data scientist, he is responsible for promoting the use of AI and data for the SBI Group and regional financial institutions.
The Big Data Division in the President's Office, where I work, is a CoE (Center of Excellence, cross-departmental) organization for AI and data utilization, and promotes and oversees the use of AI and data within the SBI Group.We also use the know-how accumulated within the SBI Group to promote and support the use of AI and data at regional financial institutions.
In the second chapter of "Patterns for Successful Financial AI," which I also helped write, I explain the targeting AI for personal loans that was developed through the efforts of my company and the regional financial institutions that I was involved in. I would like to talk about that today.
The basics and concepts of targeting AI

What is Targeting AI?
In the sales strategy of the financial business, it is common to prioritize and narrow down the customers to approach, because approaching every customer would be costly and time-consuming. For example, in the sales strategy of "sending direct mail," approaches are often prioritized based on criteria such as deposit balance and age, and the recipients are narrowed down.

Prioritize your customers and narrow your approach to reduce costs and time
*An explanatory video is provided at the end of the article.
When prioritizing, if the conditions are simple, the acquisition rate will drop. On the other hand, if the conditions for narrowing down are made complex in an attempt to increase the acquisition rate, or in other words, accuracy, the maximum number of conditions that can be manually combined by a human is about 3-4, and it becomes heavily dependent on the experience and intuition of the person in charge.
Targeting AI can automatically prioritize complex combinations of conditions, so you can expect highly accurate and successful targeting without being dependent on the experience of the person in charge.
Is targeting AI actually being used in the field?
It seems that many financial institutions are already using this technology, especially in the field of personal loans. Among personal loan products, free loans and card loans in particular are products where it is relatively easy to detect customer needs from account activity. Many banks use direct mail and outbound sales strategies to tailor their sales to their needs. By using targeting AI to analyze each customer's deposit fluctuations, loan repayment status, and deposit and withdrawal activity over several months, it is possible to identify customers with highly accurate financial needs.
Targeting AI is also being used to improve customer satisfaction. By predicting the probability of future borrowing and sending direct mail and outbound campaigns at times when customers are likely to be thinking about borrowing, the success rate and effectiveness of sales campaigns can be improved. Customers can also feel that they are being provided with information when they need it, reducing mismatches in needs and improving customer satisfaction.
What kind of data does Targeting AI use to analyze and make predictions?
Banks primarily use so-called accounting data, which includes data on the three major banking operations of deposits, loans, and foreign exchange, as well as basic information such as customer age and address, data recording deposit balances, data recording loan balances, and data recording deposit and withdrawal history. Many banks aggregate accounting data for each customer as CRM data and use it for sales activities, etc. In the case of targeting AI for personal loans, we will proceed with the construction using both this CRM data and loan execution data, which records the history of loan execution. Please see the following diagram.
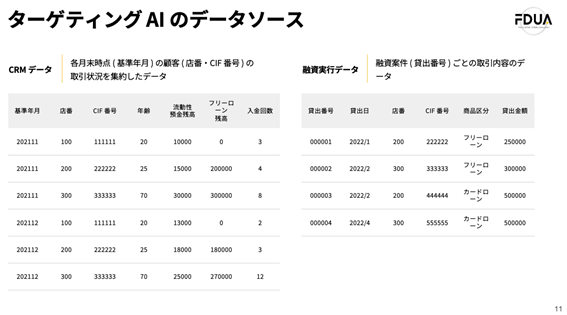
Data source for targeting AI in this case
*This data assumes that one customer holds one account (in this case, branch number and CIF number).
*An explanatory video is provided at the end of the article.
This shows an example of CRM data and loan execution data. CRM data compiles information for each customer, such as their age, deposit balance, loan balance as of the end of each base month, and the number of deposits and withdrawals within the base month. Loan execution data compiles information such as when, to whom, what product, and how much was loaned.
Basic concepts of data sources passed to AI
How do you process the data source above?
First, we will explain four perspectives on how to organize the data that will ultimately be input into AutoML, which we will refer to as AI construction data here.
1: Data for building AI is aggregated into one data set
In this case, there is multiple CRM data and loan execution data, so each will be aggregated and combined into one data.
2: Specify the "target" you want to predict and the "features" to predict.
In this case, the "target" is whether or not a loan will be made within X months of a certain reference date. The "features" are created and used by combining information from each column of CRM data or columns, such as withdrawal amount/deposit amount.
3: Define the granularity per line of data for building AI
The granularity per row of the data for building AI is determined by the definition of the "target." In this case, the "target" is whether each customer will borrow within X months of a certain base month, so we want to make predictions for each customer. Therefore, the granularity per row is the customer, that is, the store number and CIF number. Since the granularity per row is the store number and CIF number, store numbers and CIF numbers must not be duplicated in the data for building AI. As an extreme example, we could name the customer with store number 100 and CIF number 111111 as "1," the customer with store number 200 and CIF number 222222 as "2," and check to see if there are any duplicates in the data for building AI.
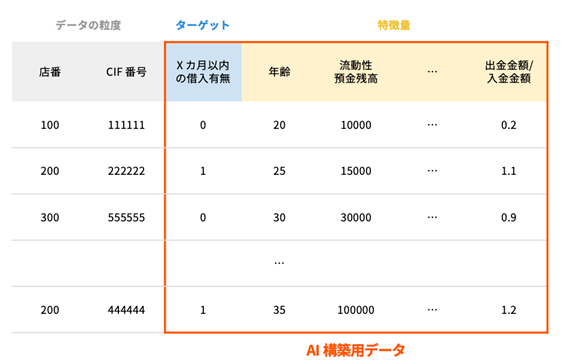
CRM data and loan execution data will be processed to create data for building AI in order to perform machine learning.
*An explanatory video is provided at the end of the article.
4: Anticipate and prevent overfitting
Finally, in this case, the store number and CIF number columns, which are the granularity of one row of data for building the AI, must be deleted. The purpose of this case is to predict whether each customer is likely to borrow money within the next X months based on whether they have borrowed money within the past X months.
Ideally, we want the AI to learn the tendencies of customers who have borrowed in the past, for example, that customers with a deposit balance of about XX and a deposit/withdrawal frequency of about XX are more likely to borrow, but if the AI is built with the branch number and CIF number columns included, it may learn that the probability of borrowing is high because the branch number and CIF number are XX. To prevent this, the branch number and CIF number columns must be deleted.
It's the same as when you give instructions to someone.
That's right. AI has made great strides, but it won't "automatically produce the expected results" just by providing it with data. People need to clarify "what they want it to do and how," and provide precise instructions and information.
Points of view and ideas for actually processing the scrutinized data
Next, we will explain how to process the data source in this case.
The processing procedure consists of the following four steps:
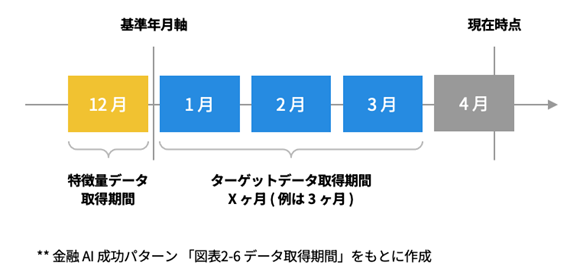
1: Deciding the data acquisition period
Decide the data acquisition period for loan execution data and CRM data. In other words, you need to determine the data from which to make predictions. In this case, the goal is to predict whether or not a loan will be taken out in the future based on past deposits and fluctuations in deposits and withdrawals.
a. Determine the period X for the target "Borrowing within X months" (in this case, X=3)
b. Determine one base date that is at least X months before the present time as the base date axis (in this case, December 2021 will be the base date axis).
c. The target data (loan execution data) acquisition period will be the loan date within X months from the base year/month axis determined in b. (In this case, it will be January, February, and March 2022, three months from December 2021, which is the base year/month axis.)
d. The base year/month axis determined in b. is used as the acquisition period for the feature data (CRM data) (in this case, the base year/month axis is December 2021).
In other words, to make predictions up to three months in the future, it is necessary to build AI using information from at least three months prior as features. By analyzing the number and amount of borrowing within X months, it is possible to determine whether "there is a possibility that a loan of XX million yen will be made within X months."
2: Create target data from loan execution data
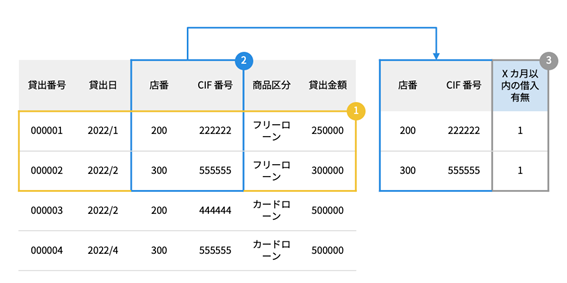
Next, we will create target data from the loan execution data. Please see the diagram below. We will extract the data for the period determined in step 1, that is, the loan dates in January, February, and March 2022, as well as the loan product for which we want to predict borrowing, in this case, free loans, and then extract only the store number and CIF number columns from the data.
Determine the data that will be the basis for the prediction. In the example above, "January to March" is set as the target data acquisition period.
*An explanatory video is provided at the end of the article.
In this case, some customers may have taken out multiple loans in a single month. This means that there may be duplicate store numbers and CIF numbers in the data source, so in that case, remove the duplicates. Finally, add a target column with all values set to 1: "Did you take out a loan within the last X months?" This completes the creation of the target data.
Target data creation image
*An explanatory video is provided at the end of the article.
① Extract only the data for the determined data acquisition period and the targeted loan products from the loan execution data
② From the data extracted in ①, extract only the store number and CIF number columns. If there are duplicate store numbers and CIF numbers, delete the duplicates and create unique data with the store number and CIF number.
③ Add a target column "Borrowing within X months" with all values set to 1 to the data created in ②.
3: Creating feature data from CRM data
Next, create feature data from the CRM data. First, extract data according to the feature data acquisition period determined in step 1. Next, add product characteristics. In this case, it's a free loan, so extract data according to the free loan conditions such as age, address, and personality type.
Next, we extract the store number, CIF number, and other columns that are effective as features, excluding the base year and month, and then perform missing value imputation and feature engineering to further improve the prediction accuracy of the AI. In this example, we create a column by dividing the withdrawal amount and deposit amount columns, such as withdrawal amount / deposit amount.
This completes the creation of feature data.
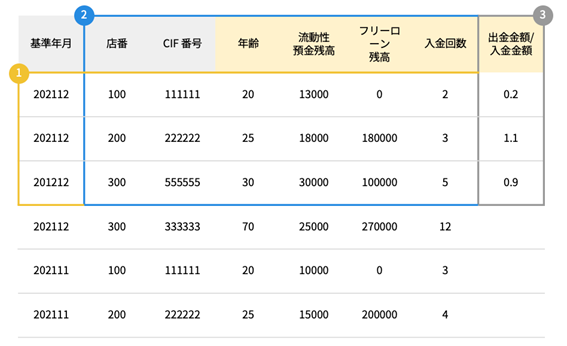
Image of creating feature data
*An explanatory video is provided at the end of the article.
① Extract data from CRM data according to the determined data acquisition period and the product characteristics (conditions such as age) of the target loan product
② Extract the store number, CIF number, and other columns that are useful as features from the data extracted in ①
③ Based on the data created in ②, perform missing value imputation and feature engineering.
4: Combine and process the target data and feature data to create data for building AI
Finally, join the target data and feature data created in steps 2 and 3. When joining, use a left outer join if you are joining target data to feature data, or a right outer join if you are joining feature data to target data, in that order from left to right.
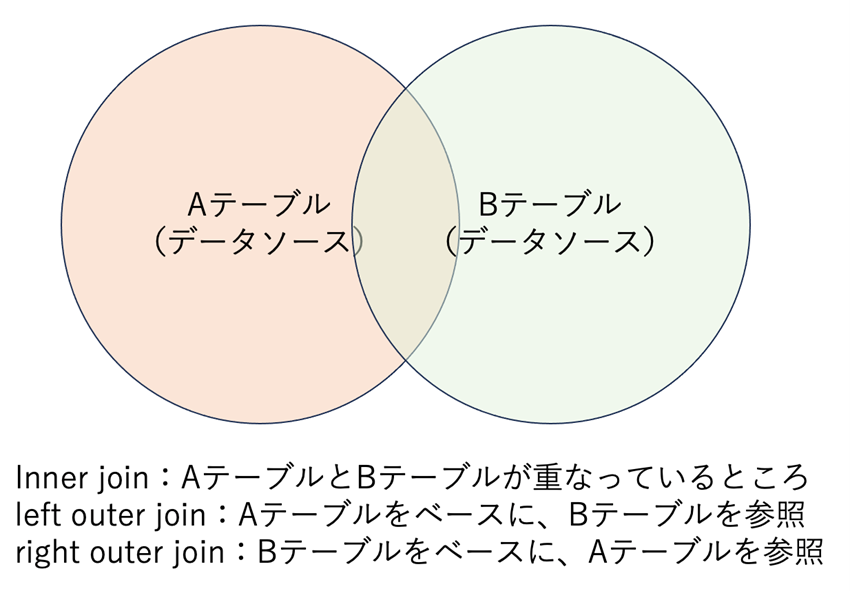
If A is feature data and B is target data, performing a "left outer join" joins the target data based on the feature data. In other words, information that is "not present" in the feature data but "present" in the target data is not applied (i.e., it is deleted).
Next, we handle duplicates and missing data. In this case, if no borrowing took place within the target data period, the value in the target's "Borrowing within X months" column will be blank, so we fill in the blank with "0". Then, to create this data for building AI, we delete the branch number and CIF number that were left in order to identify individuals, and the data for building AI is complete.
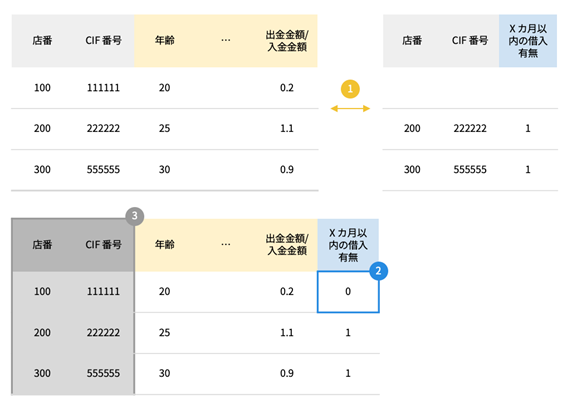
Image of creating data for building AI
*An explanatory video is provided at the end of the article.
① To obtain all feature data, combine the target data with the store number and CIF number as keys.
② When combining in ①, the target value of "Borrowing within X months" for store numbers and CIF numbers that are not in the target data will be missing, so it will be filled with 0.
③ Finally, delete the store number and CIF number columns, which are the granularity of the data.
It may seem complicated, but if you think about "what kind of target do you want the AI to predict and from what data?", it will become clear how you should process the data source.
That's right. As I said earlier, AI works better when humans clarify the purpose and information and give instructions. Imagine humans and AI working together, rather than leaving it up to the AI alone.
The first thing people should do is think about what kind of data they want to create. The four items of data for building AI mentioned at the beginning serve as a guideline when building AI, not just in finance, so I hope you will make use of them.
1: Data for building AI is aggregated into one data set
2: Specify the "target" you want to predict and the "features" to predict.
3: Define the granularity per line of data for building AI
4: Anticipate and prevent overfitting
Once you have determined these four points, your goal will be clear. You can then think about how you can process the data to achieve this goal.
Things to check when carrying out modeling
Now that you have some data to base your predictions on, what next?
Using this data source, we will build AI using AutoML (Automated Machine Learning). AutoML is a technology that can automate various tasks when performing analysis using AI. We will input the AI building data mentioned earlier into AutoML and perform modeling.
Generally, AutoML will automatically perform modeling with optimal settings, but it is a good idea to check that these settings are correct. In this case, we checked the following:
・Machine learning task: binary classification
・Upload data: Data for building AI
・Target: Borrowing within X months
・Feature type: Is each feature recognized as an appropriate type, such as numerical or categorical?
Testing method: Cross-validation using stratified sampling
The goal is to "make predictions for the target based on features." To achieve this, the key is how well you can create the data for building AI in the preliminary stages. If you think about it that way, it becomes simpler, doesn't it?
"We will verify whether it is working and how accurate it is.
We often hear people say that "AI construction is not going well," but what do you do when you feel like "things are not going well"?
It's important to note that building AI rarely works the first time. However, the main cause of this is the data used to build the AI. That's why we've been talking about "data sources" so far.
The AutoML used in this case often has a function that visualizes the model's insights. When you feel that something is not going well, you can use the insights to find data that may be causing the discrepancy in predictions and improve the data used to build the AI.
Data that may lead to discrepancies in predictions is, for example, Feature Importance, which shows how much impact each feature has on the AI, and there are cases where only certain features have a significant impact. In other words, we need to carefully examine the features that contribute most to producing the current prediction results. This can help us realize that a feature should not have been included.
Is there anything else you'd like to see?
For example, when you line up predicted values and actual measured values, as in the figure below, you may see clearly different trends.
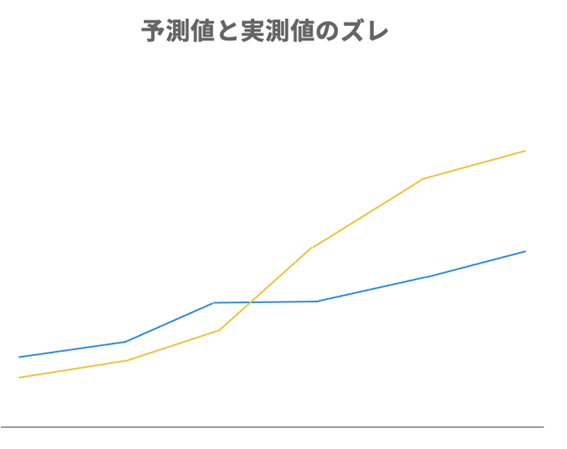
*An explanatory video is provided at the end of the article.
This means that the AI is not making good predictions. In this case, you may be able to improve the accuracy of the AI by dividing the data by value or range and building multiple AIs.
"The cause lies in the data used to build the AI" = So, first, we review the data source. On the other hand, we compare the actual measured values with the predicted values to identify "where the discrepancy in the prediction occurs." I see, so when Mr. Nabekura says "building AI doesn't work in one go," it means that accuracy is improved over time.
There are two types of AI accuracy verification: practical verification, where actual measures are implemented, and desk-top verification, where past data is used. AUC is one of the accuracy metrics for AI in desk-top verification, and is calculated automatically by many AutoML programs.

Desk verification, AUC value guideline
*An explanatory video is provided at the end of the article.
Although the accuracy of AI cannot be measured by the AUC value alone, we can intuitively judge that accuracy is good if it is closer to 1, and poor if it is closer to 0.5. For now, it is a good idea to aim for around 0.6-0.8.
Furthermore, "AB testing," a method familiar to those with marketing experience, is also effective for AI in practical verification. Data extraction is performed using two methods, one using existing methods and one using AI, and the results are compared to verify accuracy.
"The more effort you put into preparation, the easier it will be to operate."
It's been a long journey so far, but we've set our objectives, organized our data sources, and inputted them into the AI. Now that we're ready to test it, it's time to put it into operation. Could you tell us what you think about the operation?

A review of the AI operation flow
*An explanatory video is provided at the end of the article.
In fact, the operation of the targeting AI we're talking about today isn't that complicated. We obtain CRM data for the most recent base month and year, process the data in a similar way to creating feature data, and then use the AI to make predictions. The output is the borrowing probability for each customer, that is, for each store number and CIF number, so we obtain the number of targets in descending order of borrowing probability, implement the measures, and then verify them. The more effort we put into preparation, the less we have to do in operation.
However, using AI is not just about creating and managing targeting lists.
Recently, the monitoring and management of AI, known as Machine Learning Operations (MLOps), has become important. The first thing to pay attention to is "data drift."
Data drift monitors whether the prediction data entering the AI has changed compared to the data when the AI was created. An extreme example is adding a data source during operation, thinking, "If we add this information, perhaps the accuracy will improve?" "Until now, we've used increments of 10,000 yen, but now we've changed it to increments of 1,000 yen," and even small changes like these can affect the accuracy if not communicated to the AI.
Thank you for talking about everything from the big picture to specific cases. Do you have any final words?
In addition to this, it is necessary to monitor for deterioration in accuracy, that is, whether the AI predictions and actual results are falling, as well as to check whether the systems are working properly together. AI is evolving rapidly. In the same way, society and the market are also changing, and appropriate adjustments must be made by humans. Furthermore, even if predictions are being made properly, if there is a problem between the systems, such as an internet line failure, the predicted results will not be output.
"AI is difficult," I always want to tell people, "That's not true!" Have you ever tried to get an AI to find a ring you dropped in the desert? By writing down as much information as you can think of, such as when you realized you lost it and the route you took, and then extracting only the information necessary to "find" it, the AI will provide powerful support in quickly finding your ring.
I hope you will find some hints for utilizing AI from this article and the book "Patterns for Successful Financial AI."
Written by Financial Data Utilization Promotion Association
"Success Patterns for Financial AI"
Now on sale and a big hit!
"FDUA Financial Data Utilization Promotion Association Tie-up Project" video
On Saison Technology's official YouTube channel,
We would like to introduce an explanatory video by Yuki Nabekura of SBI Holdings, Inc., who was in charge of writing Chapter 2.
Please see also.
Related Content
-

Survival Strategy in an AI-driven Society: How will humans live in an artificial super-intelligence society?
-

Applicable AI that can quantitatively judge and evaluate core credit operations of banks - Tips for developing credit screening AI -
-

Grasp insights that cannot be grasped through numbers from text and qualitative information! ~ Characteristics of text classification AI ~