Applicable AI that can quantitatively judge and evaluate core credit operations of banks - Tips for developing credit screening AI -
Credit and screening are important not only in banking but in all industries. For a long time, these were areas where the experience and intuition of veterans were essential, but with the advent of AI, we can expect to see more accurate judgments and knowledge sharing.
This series introduces the use of AI and success stories. In this fifth installment, we spoke with Tomoyuki Yamane, an engineer at Mizuho Daiichi Financial Technology, which supports the technology side of Mizuho Bank, one of Japan's megabanks, about the key points and tricks behind the development of "credit screening AI."
▼Profile
Financial Data Utilization Promotion Association, Planning and Publication Committee
Mizuho Daiichi Financial Technology Co., Ltd.
Data Analytics Technology Development Department
Senior Financial Engineer
Tomoyuki Yamane
*Titles and affiliations are those at the time of interview.
Credit screening AI aims to reduce the amount of work required for credit screening
First, could you please introduce yourself, Mr. Yamane?
He majored in mathematical optimization and machine learning at a science university and graduate school, graduating in 2016 and joining Mizuho Bank. After joining the bank, he worked in credit risk management, and in 2020 was seconded to his current position at Mizuho Daiichi Financial Technology. His main responsibilities include developing AI for credit screening for corporate and individual customers, and building operational flows. He is also involved in research and development into the application of natural language processing technologies, including ChatGPT, to the financial sector.
Can you tell us about Mizuho Daiichi Financial Technology?
Mizuho Daiichi Financial Technology is a unique company founded in 1998 with three parent companies: Mizuho Bank, Dai-ichi Life Insurance, and Sompo Japan Insurance. With a mission to "illuminate the future with science and insight," the company has proactively adopted techniques in new fields such as data science in response to technological advances.
Since our founding, we have honed our expertise in mathematical technology and data science, based on financial engineering. In addition, approximately 70% of our staff have graduated from graduate schools, and just under 20% of them have doctoral degrees. We also have members in their 20s and 30s with diverse backgrounds, and we are proud to be a vibrant organization that brings together the knowledge and technology of the Mizuho Group and, by extension, the financial industry, to lead the industry.
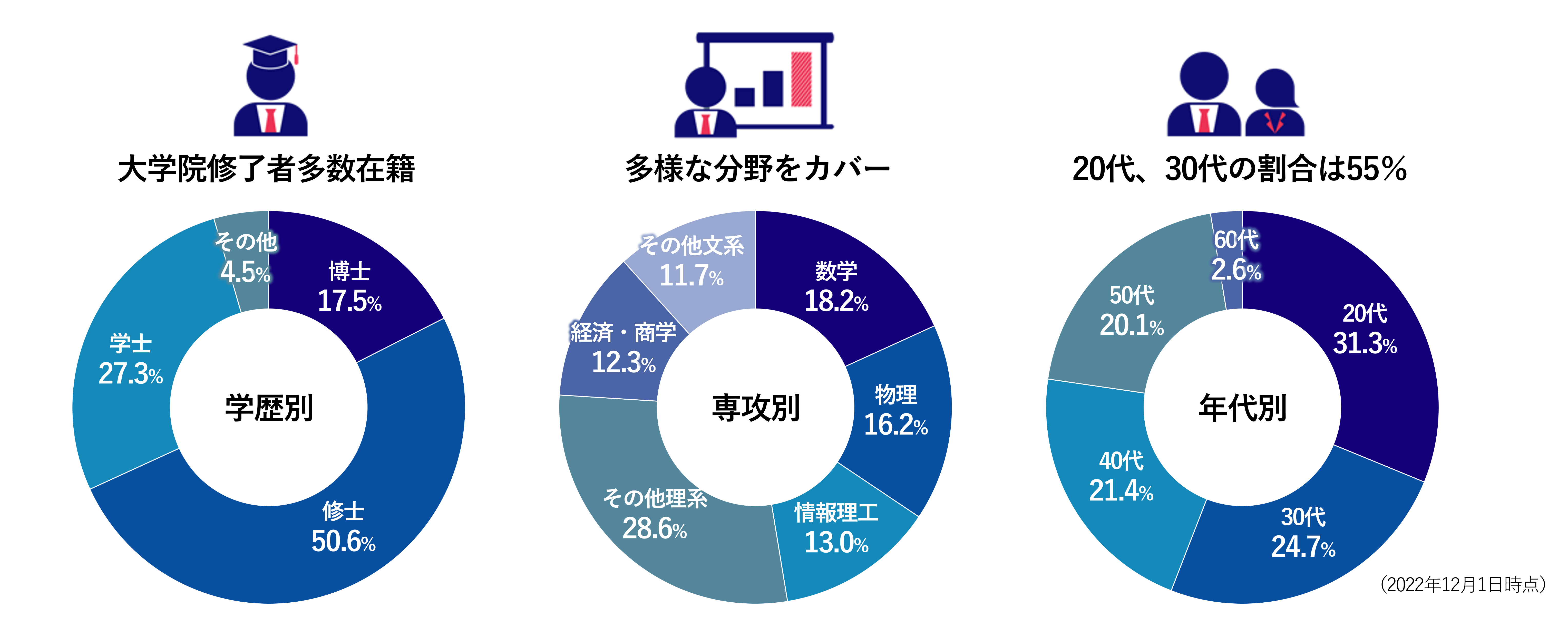
About Mizuho Daiichi Financial Technology employees
*An explanatory video is provided at the end of the article.
This time, we will explain the screening AI that we have developed and are operating.
What is Inspection AI?
First, let me explain what "bank credit" is. Bank credit means "taking deposits from customers and lending them to companies." Banks earn revenue from the difference between the interest rate they charge when lending to companies and the interest rate they pay back on the deposits they receive from customers.
Identifying lenders (screening) and providing funds to the right companies is an important task not only for the bank's profits but also for preserving customer deposits and stimulating economic activity. However, as the number of lenders to be screened increases, there is a shortage of bank staff with the necessary screening know-how. This has created a need to replace part or all of the screening process with machine learning models and AI.
"Screening AI," which automates screening work using AI, is expected to not only reduce the amount of work required for screening work, but also support humans in making lending decisions and share screening know-how.
What kind of data does the screening AI need?
The materials that AI uses to make its judgments include "past loan information" such as past loan amounts, monthly repayment amounts, and whether or not there have been any late payments, "account information" such as deposit balances and remittance amounts, and "company information" such as the date the account was opened and asset size. The mainstream approach is to input these information and use machine learning and statistical methods to build a regression model that estimates the probability of default.
Can you elaborate on the probability of bad debt?
The probability of a loan default refers to the probability that a borrower will fail to repay the loan, i.e., default (failure to fulfill the debt). It is also known as the default rate, or PD, which stands for Probability of Default, and is an important indicator for banks (hereafter referred to as PD in this document). Credit screening AI estimates this PD from the aforementioned factors and uses it to decide whether to approve a loan and to offer an interest rate.
The decision-making criteria input into the review AI and the results are summarized in the figure below.
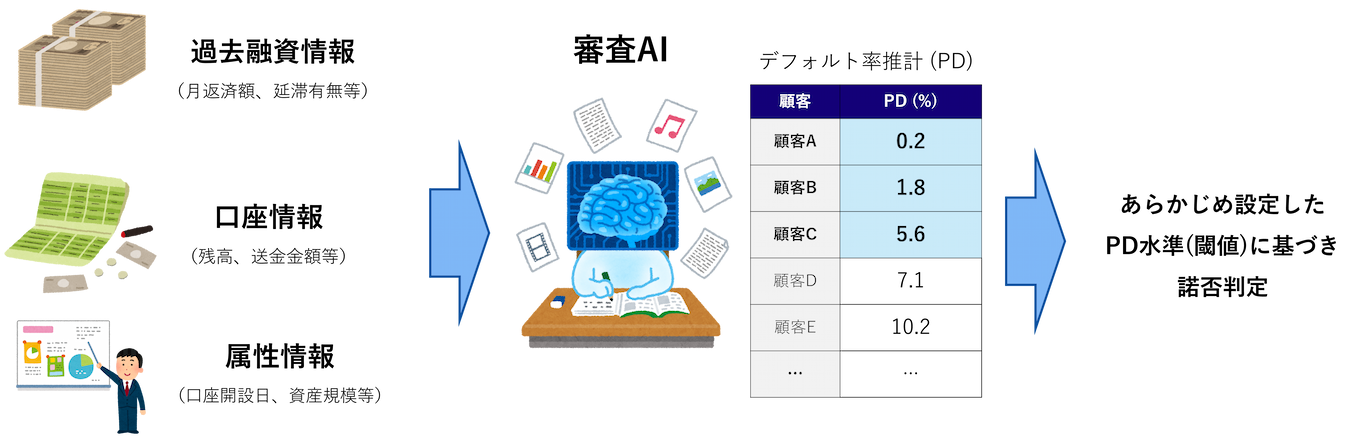
Data required for screening AI and the desired results
*An explanatory video is provided at the end of the article.
The above is an example where the PD threshold for approval/rejection is set at 6%. If the PD exceeds 6%, the loan will be rejected, and if it is below 6%, it will be approved (center of the image above). Until now, this approval/rejection decision was made by experienced bankers, who took into account data such as past loan information and account information (see the left side of the image above), as well as qualitative information such as interview records. By utilizing screening AI, it is possible to quantify the borrower's credit status from this data, leading to more accurate credit decisions and more efficient screening operations.

The data to be entered can be broadly divided into three categories:
I would like to hear more about the data used to build the review AI model.
In this case, we are assuming three main types of data: "past loan information," "account information," and "attribute information." First, it is assumed that all data includes the CIF number to identify the customer, the base month and base date indicating the year and month of the data, so please check and format the data in advance.
"Past loan information" is divided into delinquency history and loan history.

Explanation of "Past Loan Information"
*An explanatory video is provided at the end of the article.
Delinquency history is information about the delinquency status of each customer for each base month. This serves as the training data for learning, i.e., the basis for creating default flags, and is often used as a feature for PD estimation. Loan history also includes information such as the amount of loans executed in the past, the execution date, the purpose of the funds, and the current loan balance.

Explanation of "Account Information"
*An explanatory video is provided at the end of the article.
Next is data related to "account information." This is divided into deposits and withdrawals and account balances. Deposits and withdrawals are transaction-based details, so they are processed as monthly/yearly summary information. Account balances include balance information for yen/foreign currencies, regular/fixed term deposits, etc. Before analyzing or processing, be sure to check whether the balance aggregation definition is the end-of-period balance or the average balance during the period.

Data type used
*An explanatory video is provided at the end of the article.
Finally, there is "attribute information" data. While the previous two data are generated by both individuals and corporations, this information is often different for each individual and corporation. Account items such as liquid deposits, fixed assets, and equity capital are specific to corporations, but for individuals, the equivalent would be address and whether or not they have purchased investment trusts.
A typical example of optional data is alternative data. This is information obtained through collaboration with business companies, and is data that has been expected to be particularly useful in recent years. When using this data, it is important to pay attention to whether the aforementioned data groups can be linked to the same customer using CIF, and whether the data coverage is sufficient.
The data processing flow
How will you process this data?
The data processing is carried out as follows:

Data processing steps
*An explanatory video is provided at the end of the article.
First, we extract samples for model building. When developing a screening AI, the loan products that use the screening AI are often newly designed, so there may not be any past loan records for that product. In such cases, we select transactions from the bank's past transactions that are as similar as possible to the loan products that use the screening AI, and extract them as samples for model building.
Extraction is often based on the purpose of funds, loan period, execution amount, etc., but to prevent reversals due to misunderstandings between the parties involved, it is a good idea to decide on extraction policies through early discussions with the product and risk departments.
What factors do you consider when deciding the period for acquiring sample data?
Obviously, you start by deciding "what you want to use." First, define the observation period for the features (how many months of information, such as balances and deposits and withdrawals, should be considered from the reference date for the loan occurrence). The longer the observation period for the features, the more information can be captured, but simple averaging will diminish the importance of the most recent information, so it is important to decide and adjust while looking at the actual accuracy of the AI.
Next, define the default observation period (how many months after loan execution the default conditions must be met before the loan is considered a default). One year is usually the standard, but if the loan to which AI is applied is expected to be a long-term loan such as five years, the observation period may be extended accordingly. A default flag is also assigned. Define the default conditions for each month, and use flag data to indicate whether the default conditions are met within the defined default observation period. For default conditions, refer to the definition within the row, or if there is a definition for each product, use that as well.
How about specifying the target sample? Will it be debtors?
It depends on the amount of data and the situation. Ideally, one borrower should be one sample, as this will determine whether or not to grant a loan, but if the amount of data is small, the accuracy of the screening AI may decrease. Depending on the amount of data and product characteristics, one loan to a borrower may be used as one sample.
Transaction data, such as deposit and withdrawal data, may also need to be adjusted depending on the situation. Various processing methods are possible, such as period averages, standard deviations, and counts, but please consider reprocessing and adjustments as necessary while monitoring the accuracy of the AI.
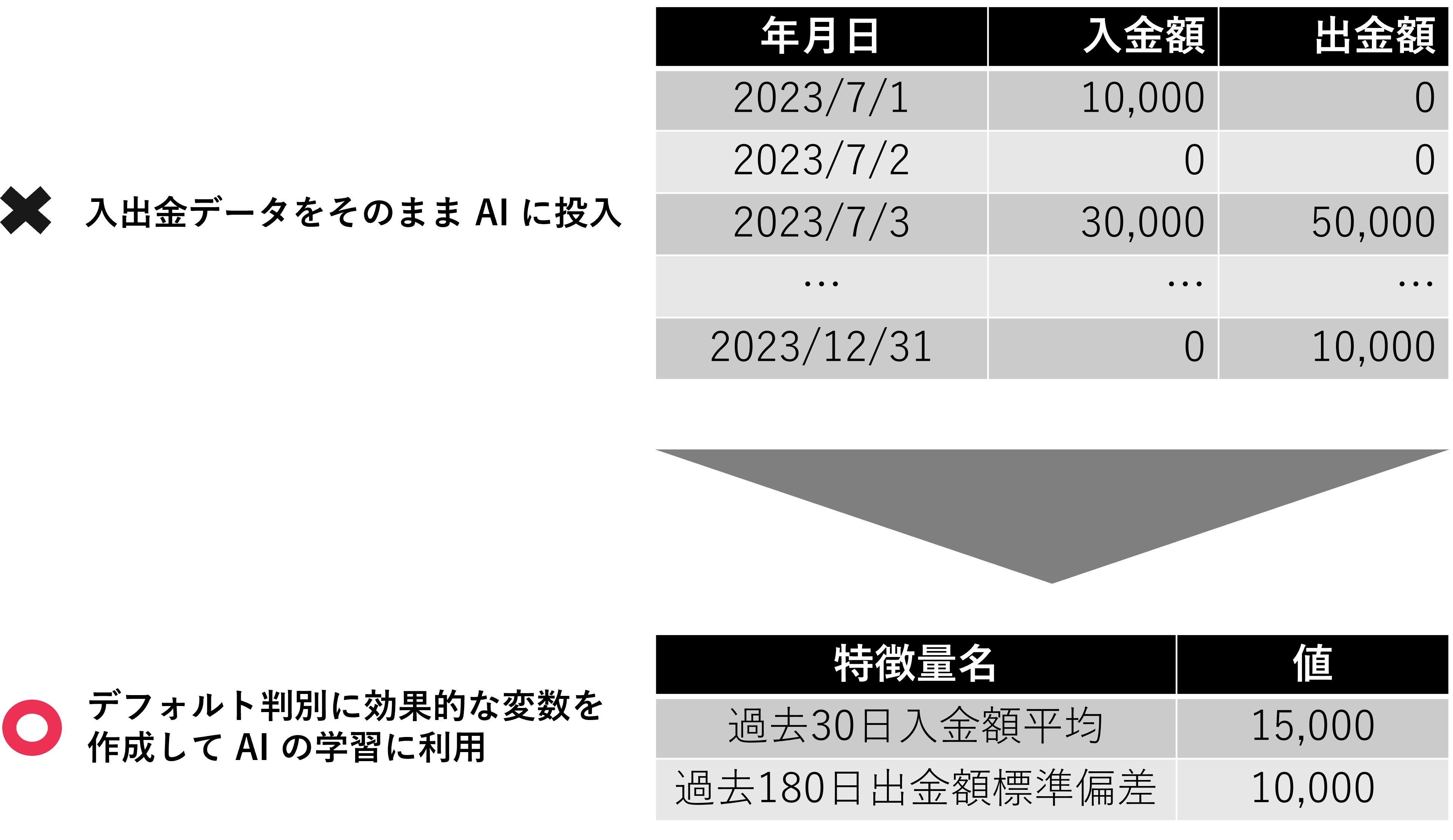
Basic concepts of deposit and withdrawal data (transaction data)
*An explanatory video is provided at the end of the article.
When splitting the data, select random splitting, time series splitting, etc. If splitting randomly, use stratified k-fold or similar techniques to ensure that the PD levels of the training and validation data are equal. Also, to prevent overfitting (described later), make sure that the same debtors and loans do not appear in both the training and validation data.

Data division method and points to note
*An explanatory video is provided at the end of the article.
Finally, feature processing is performed. This is often done using BI tools to analyze data from various angles and axes, exploring which variables affect PD. While this can be done mechanically based on numbers, analyzing the correlation between financial variables and creditworthiness requires appropriate domain knowledge to interpret the results. As an example, consider debt repayment years (interest-bearing debt ÷ operating profit). Generally, debt repayment years have a negative correlation with creditworthiness (the smaller the number, the higher the creditworthiness). However, when the denominator, operating profit, becomes negative (operating loss), if interest-bearing debt is positive, debt repayment years will also become negative. This will result in a smaller value than the debt repayment years (usually a positive value) for a company with an operating profit, which will ultimately be interpreted as high creditworthiness. When deriving implications from the results of fundamental analysis, always consider the implications of these financial indicators.
It is important to make adjustments as you operate the system
Could you explain how you verify accuracy?
In accuracy verification, in addition to AUC, which is often used to evaluate general machine learning models, AR value is often used in credit risk management. Roughly speaking, AR value is a value that evaluates "the degree to which default samples are concentrated near the beginning when samples are sorted in order of highest predicted PD." The closer this AR value is to 1, the more accurately the AI can detect defaults.
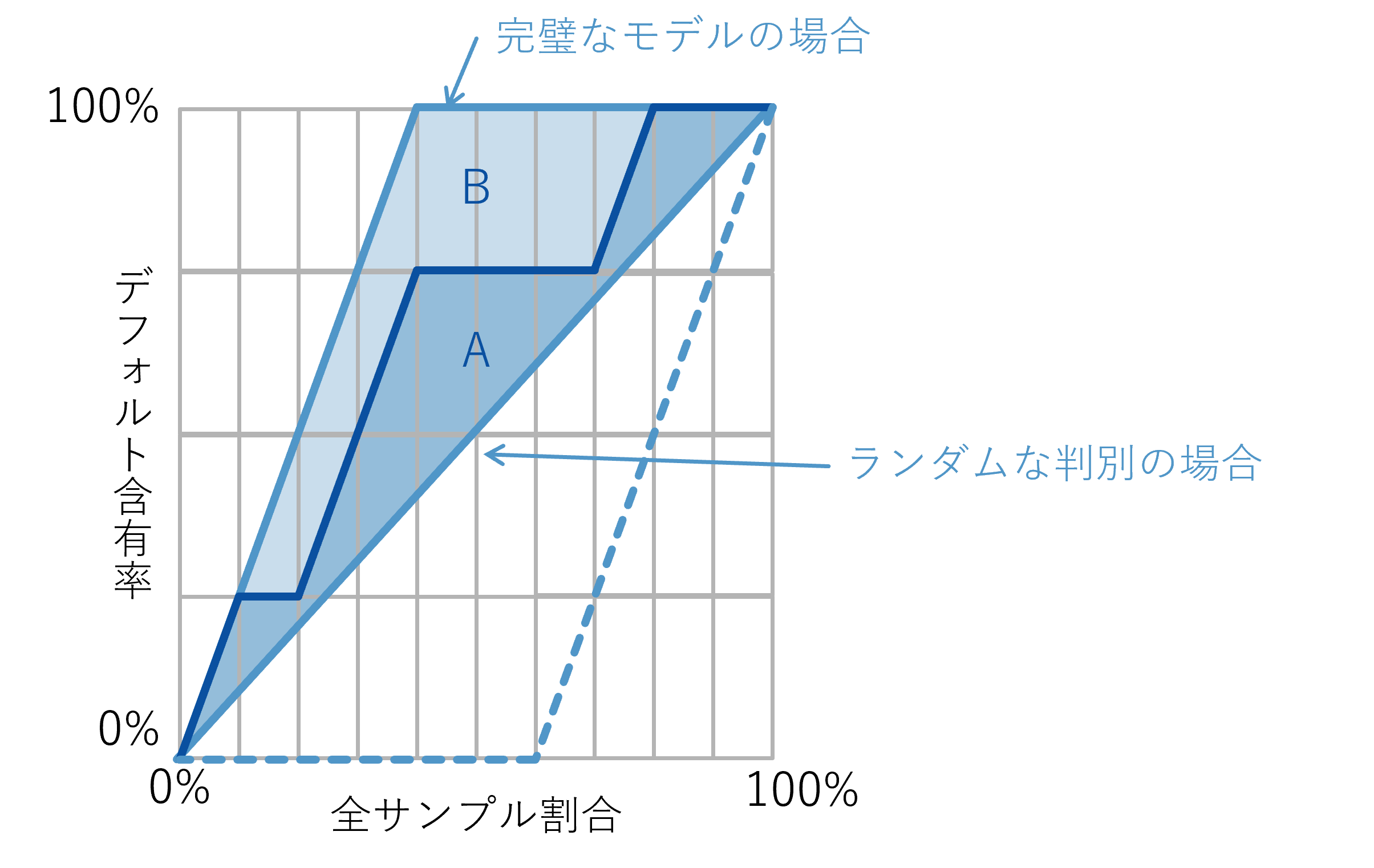
Default sample content when samples are sorted in descending PD order
*An explanatory video is provided at the end of the article.
First, please note that while the AR value evaluates the average performance of AI at each threshold, the actual PD level depends on the threshold. The threshold is determined by risk appetite, i.e., the desired approval rate for loan products, while the AR value quantifies "how efficiently non-defaulting borrowers can be acquired when the number of approved borrowers is increased." When building a model, it is important to aim for the highest AR value possible, while also setting the threshold level in collaboration with relevant parties, based on the perspective of "how much risk you are willing to take with that loan product."
Could you tell us about some points to be careful about when operating this system?
The important thing to remember about operation is that "construction and operation are not the end." By monitoring the status during operation and continuing to fine-tune the features and examine the model, you can maintain and improve accuracy.
Monitoring is important to find areas that need adjustment. Monitoring is carried out from the same perspective as for general machine learning models, but due to the long default observation period and the difficulty of conducting A/B testing, it can be difficult to collect actual data for screening AI. In such cases, unsupervised monitoring may be performed, such as checking whether there are any changes in estimated PD or feature distribution compared to the previous month.
The predicted PD obtained by the screening AI is used to determine whether or not to approve a loan and to set loan conditions, as mentioned earlier. By applying a loan interest rate mapping table to this predicted PD, it is also possible to mechanically assign interest rates.
Thank you. Finally, could you give us some tips on developing and operating screening AI?
When it comes to screening AI, using complex AI does not necessarily "increase accuracy." Be careful of "overfitting," not just in screening AI. As an example of overfitting, consider solving past exam questions in order to pass an exam. While solving multiple past exam questions is effective in grasping the question trends, memorizing every word and answer word for word will actually reduce your ability to adapt to unknown problems. In the world of machine learning, this situation of "adapting too much to past results and losing the ability to adapt to unknown problems" is called "overfitting." Don't end your verification with "high initial accuracy," but instead conduct ongoing accuracy verification and model selection by providing feedback on verification results in actual operation.
Finally, I would like to make two comments regarding the management of the screening AI development project. First, the development of the screening AI we inquired about this time involves multiple stakeholders, including the loan product department, risk department, and compliance department. Since each perspective may affect the requirements for AI development, it is important to provide detailed progress reports to stakeholders and reduce the risk of relapse.
Second, when developing screening AI, data collection and processing make up the majority of the work. This basic data processing often accounts for up to 70% of the total man-hours, and the accuracy of the AI being developed may not be estimated until the end of the project. Therefore, it is important to plan the schedule with ample time to allow for basic tasks such as data aggregation and processing, lower the priority of advanced feature processing, and build a prototype model first to speed up the accuracy estimation.
Written by Financial Data Utilization Promotion Association
"Success Patterns for Financial AI"
Now on sale and a big hit!
"FDUA Financial Data Utilization Promotion Association Tie-up Project" video
On Saison Technology's official YouTube channel,
We would like to introduce an explanatory video by Tomoyuki Yamane of Mizuho Daiichi Financial Technology Co., Ltd., who wrote Chapter 6.
Please see also.
Related Content
-

Survival Strategy in an AI-driven Society: How will humans live in an artificial super-intelligence society?
-

Grasp insights that cannot be grasped through numbers from text and qualitative information! ~ Characteristics of text classification AI ~
-

Making real estate investment more convenient and high-quality. The key is to create a model that is easy for people to interpret - Focus of value calculation AI -