データ活用を支えるデータ基盤の重要性 データパイプライン選定の9つの基準


データ活用のための基盤構築には、データの整備・統合が重要です。特にデータパイプラインの選定は、データ活用の効率を大きく左右します。この記事では、データ基盤の重要性とパイプライン選定時に考慮すべき9つの基準について解説します。
データ活用を加速するための必須要素:データ基盤の整備
データ活用に取り組むうえで、データから価値を引き出すための基礎となるため「データ基盤」は非常に重要です。データ基盤とは、データを集約・整備・保存・分析するための技術的な基盤のことで、データウェアハウス(DWH)、データレイク、データパイプライン(ETL/iPaaS)、分析ツールなどが含まれます。
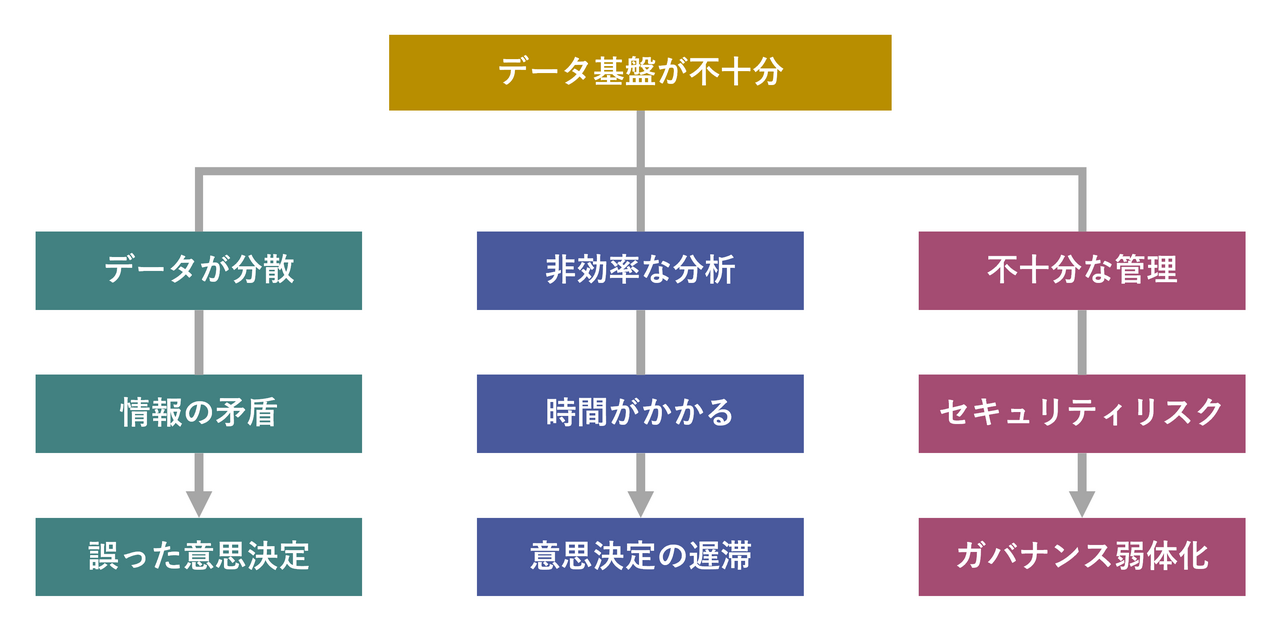
データ基盤が不十分だと、情報が分散し、整合性を欠いたデータによって誤った意思決定を引き起こすリスクが高まります。分析の効率も悪化し、迅速な意思決定が困難になります。またセキュリティリスクやガバナンスの問題も発生し、ビジネスの成長に悪影響を及ぼす可能性が高くなります。
データ基盤の整備は、単にデータを保存・管理するための技術的な要素にとどまらず、企業がデータを戦略的に活用するための基盤を提供する重要な役割を担っています。
データ基盤構築の課題となる「データの整備と統合」
データ基盤の構築において多くの企業が直面する課題は、異なるソースからのデータを統合することです。
企業内には異なるシステムやアプリケーションからさまざまなデータが生成されています。これら複数のシステムや部門から集められるデータの整合性を保ちつつ、全社で活用できる形に統合することは非常に難しく、時間とリソースを要します。例えば、顧客データや販売データ、在庫データなどが異なるフォーマットで保存されている場合、これらを一元的に統合し可視化するための仕組みが必要となります。
データ基盤におけるデータパイプラインの役割
データ基盤において、データパイプライン(iPaaS、ETLとも呼ばれます)は非常に重要な役割を果たします。
企業内には異なるシステムやアプリケーションなどさまざまなデータソースがあり、これらのデータを一元的に管理し、分析や活用に役立つ形に変換するためには、データパイプラインが必要不可欠です。

1. 効率的なデータ統合
データパイプラインは、異なるソース(データベース、クラウドストレージ、外部APIなど)からデータを収集し、それらを一元化する役割を果たします。手動でデータを統合する場合には膨大な時間とコストがかかり、人的ミスも発生しやすくなります。データパイプラインによりこれらのプロセスが自動化され、より効率的に、より正確にデータを統合することが可能となります。
2. データの前処理と変換
集められたデータは、そのままでは分析に適さない場合が多いです。データパイプラインはデータのクレンジングと変換を行います。これにより欠損値の補完や重複データの排除、データ型の変換、標準化などを実施でき、品質の高いデータセットを作成できます。データが一元化され、必要な形式に整えられることで、全社的にデータの可用性が向上します。
3. リアルタイムデータの統合
従来のバッチ処理型のデータ統合に加え、現代のビジネスではリアルタイムでのデータ統合が求められます。データパイプラインは、リアルタイムデータの収集と処理を行うことで、顧客の行動や製品の需要、在庫状況などの即時反映が可能となり、より迅速な意思決定をサポートします。リアルタイムでデータが統合されることで、即時にビジネスの状況を把握して、迅速な意思決定が可能になります。
4. 異種データソースの統合
複数の企業やパートナーが異なるシステム、データ形式、セキュリティ要件を持っている場合、データの統合はより複雑になります。データパイプラインはこれら異なるタイプのデータを効率的に統合し、分析に使える形に変換します。データパイプラインを使うことで、ビジネスの全体像を把握するために必要なデータを一貫した形で利用できるようになります。
5. データフローの自動化
データパイプラインはデータの収集から変換、保存までの一連の流れを自動化します。この自動化により、手動でのデータ統合作業が減り、エラーのリスクも低減します。また定期的にデータを更新するためのスケジュール設定ができるため、データ基盤が常に最新の情報を保持し続けることができます。
6. スケーラビリティ
ビジネスが成長しデータ量が増加した場合でも、データパイプラインを使うことでスムーズにスケールアップできます。手動でデータを統合する場合は増加するデータ量に対応するのが難しいですが、パイプラインは自動化されているため、大量のデータにも対応可能です。
7. 開発容易性
通常、データパイプラインプロセスをIT部門に依存すると、業務の進行が遅れ、機会損失を招く可能性があります。そこで、ITスキルがなくても扱えるデータパイプラインツールを選定することが重要となります。業務担当者が独自にデータの流れを管理できることは、問題解決のスピードを加速させ、柔軟にビジネス環境に対応するために不可欠です。
8. 異常検知と復旧
データパイプラインは多くの処理ステップを経てデータを集約し、分析可能な状態にしますが、その過程でエラーが発生することは避けられません。データの欠損、異常値、フォーマットの不一致などが原因で処理が途中で停止したり、誤ったデータが流れてしまうリスクがあります。問題を素早く特定し、データパイプラインの運用を安定させるためには、柔軟なエラーハンドリングの仕組みが重要になります。
9. セキュリティとコンプライアンス
データには個人情報や機密情報が含まれることが多く、その取り扱いには高度なセキュリティ対策が必要です。セキュリティが不十分だと、サイバー攻撃や内部の不正行為によってデータが不正にアクセスされ、企業の信頼性やブランドイメージに深刻なダメージを与える可能性があります。また適切なコンプライアンス管理がなされていないと、法的な罰則や訴訟のリスクが生じます。セキュリティとコンプライアンスの仕組みがしっかりしていれば、企業は法的リスクを回避し、データ利用に対する信頼性を高めることができます。
オンプレも、クラウドも。自由自在なデータパイプライン HULFT Square

iPaaS型データ連携基盤 HULFT Square(ハルフトスクエア)
HULFT Squareは、「データ活用するためのデータ準備」や「業務システムをつなぐデータ連携」を支援する日本発のiPaaS(クラウド型データ連携プラットフォーム)です。各種クラウドサービス、オンプレミスなど、多種多様なシステム間のスムーズなデータ連携を実現します。
データパイプラインにHULFT Squareをオススメする9つの理由
HULFT Squareは、データパイプラインに求められる6つの要件に加え、開発生産性と安全性につながる3つの要件を満たすことができます。
1. データ統合の多様性
データパイプラインは、様々なデータソース(データベース、CSV、API、SaaSツールなど)からデータを効率的に抽出できる必要があります。
HULFT Squareは豊富な連携コネクターを備え、多くのSaaSプロバイダーが提供するREST API(RESTful API)はもちろん、JDBC、FTP、IMAP/POP3/SMTPといった多様なプロトコルとの接続実績があります。国内外の150を越えるデータソースに対応しています。
2. 柔軟なデータ変換・加工機能
データパイプラインには、データがDWHにロードされる前に必要な変換(例えばデータ型の変更や集計処理など)を実行できる柔軟なETL機能が必要です。
HULFT Squareは、データの結合、変換、集計といった基本的な変換機能はもちろん、ひらがな/カタカナ変換、和暦/西暦変換、全角/半角変換、漢数字/英数字変換など、日本特有の変換要件にも柔軟に対応できます。
3. リアルタイム処理とバッチ処理
リアルタイムでデータを反映し、即座にビジネスインサイトを得たい場合、リアルタイムデータストリーミング機能が必要です。一方、大量のデータを定期的に処理する場合には、バッチ処理に適したパイプラインを選ぶ必要があります。
HULFT Squareは、スケジュール起動、REST APIによる起動、ファイルの受信による起動など、多様なイベントを契機としてパイプラインを実行することができます。
4. データ形式の差異吸収
データパイプラインは社内外に存在する多様なデータソース、フォーマット、プロトコルを効果的に処理・統合できる柔軟性を持つ必要があります。
HULFT Squareは、接続先のサービスやシステムの特性に応じた「3つのつなぎかた」で柔軟に連携することができます。専用コネクターの有無、接続先サービスから提供されるAPIの種類、システムのネットワーク環境などに応じて最適なつなぎかたを選択していただけます。
5. オーケストレーション
複数のデータ処理ステップが必要な場合、データの抽出・変換・ロード(ETL)のフローを管理するためのオーケストレーション機能が求められます。またタスクが依存関係を持つ場合には、適切なタイミングで処理が行われるように管理する機能が必要です。
HULFT Squareは、条件分岐や繰り返し処理、並列実行・待ち合わせ処理、トランザクションのコミット・ロールバック制御などの豊富な制御機能により、要件に合わせたきめ細やかなデータフロー管理を実現できます。
6. スケーラビリティ
ビジネスが順調に成長すると、データウェアハウスに流し込むデータ量が増大します。データパイプラインにはビジネスの成長スピードに追随できるスケーラビリティ(水平・垂直スケーリングの対応力)が求められます。
HULFT Squareは、自由にスケールアップ/スケールアウトを行うことができ、想定されるデータ件数や求められる性能指標に応じて適正なスケールを選択できます。スモールスタートから大規模運用まで幅広い用途に対応できます。
7. ノーコード/ローコード対応
データ連携技術に関する専門的なスキルがない利用者にとっては、視覚的にデータフローを構築できるノーコード機能が備わっていると、多様な役割の担当者がデータ活用に関与しやすくなります。
HULFT Squareなら、ドラッグ&ドロップによる直感的な操作によってユーザー部門でもスピーディーに開発が可能です。さらに充実したドキュメントとサクセスナビによる丁寧な手引きによって無理なくステップアップでき、効率的に学習を進めていくことが可能です。
8. 柔軟なエラーハンドリング
データパイプラインが途中でエラーに遭遇した場合、リトライ処理やエラーロギング、通知機能が必要です。
HULFT Squareは、データの転送や処理中に発生するエラーや問題を検出し、適切に処理します。エラーの種類、発生場所、詳細な内容(スタックトレースなど)をログに記録し、エラーが発生した際に担当者へ通知を送ることで迅速に問題に対処することができます。エラー発生時の挙動は自由にカスタマイズできます。
9. データ保護とプライバシー基準
パイプラインを通じて転送されるデータは暗号化されている必要があります。特に機密性の高いデータを扱う場合には、強力なセキュリティ対策が求められます。
HULFT Squareは、GDPR、CCPA、SOC2 Type2に準拠し、国や地域を問わず安心してお使いいただけます。

ユースケース
データパイプラインとしてHULFT Squareを活用したユースケースをご覧ください。


HULFT Squareのご相談はこちら
記事を書いた人