人とAIが強力なタッグに、データの考えかたから運用までを流れで知る ~ターゲティングAIパターン構築~
2015年、「ディープラーニング(深層学習)」に注目が集まった。同技術は、2006年に提唱、開発が続けられ2010年代には頭角を表し始め、人による補完が必要だった特徴の抽出、比較、分析がAIだけで可能となり、AI開発を飛躍的に加速させた。日進月歩で進化しつづけるAIはイラストやテキスト生成など身近なことも行えるようになったAIだが、ビジネスシーンでも古くから注目が集まっている。
特に銀行、金融業界では高いセキュリティ性が求められることのほか、支店などの運用で膨大なコストがかかることから、AIの活用に早くから着目していた。どの業務、どの分野にAIを導入し、活用できるのかを各行、各企業それぞれに頭をひねり試行錯誤をしていた。今回は、2023年2月に発刊した書籍『金融AI成功パターン』で第二章の執筆を担当したSBIホールディングス株式会社 社長室ビッグデータ担当の鍋倉由樹氏に、金融業界でのAI成功パターンを解説いただいた。
▼プロフィール
一般社団法人金融データ活用推進協会 企画出版委員会
SBIホールディングス株式会社 社長室ビッグデータ担当
鍋倉由樹氏
※役職や所属は取材時のものです。
金融業界のリーディングカンパニーが組織したAI専門部隊のひとり、鍋倉由樹氏
最初に鍋倉さんが所属するSBIホールディングスについて教えていただけますか?
ベンチャー・キャピタル事業を行うことを目的として、ソフトバンクの子会社のソフトバンク・インベストメントとして1999年に設立。2005年に現在のSBIホールディングスに商号変更しました。オンライン証券、銀行、保険などの金融サービス事業を中心に成長を続け、2023年3月期から金融サービス事業、投資事業、資産運用事業、暗号資産事業、非金融事業の5事業へと変更。「金融を核に金融を超える」を実現するべく、先進技術を活用した商品・サービスの改善や新たなビジネスの創出に力を入れるほか、地域金融機関と密に連携し、地方創生の取り組みにも注力しています。
鍋倉さんはSBIホールディングスでどのような業務に携わっていますか?
大学で宇宙放射線物理を専攻後、2017 年に SBI ホールディングスに新卒で入社。データサイエンティストとして、SBIグループおよび地域金融機関のAI・データ活用の推進を任されています。
私が所属する社長室ビッグデータ担当は、AI・データ活用の CoE(センターオブエクセレンス、部署横断型) 組織として、SBIグループのAI・データ活用の推進・統括を行っているほか、SBIグループで蓄積されたノウハウをもとに、地域金融機関へAI・データ活用を推進支援しています。
私も執筆に関わった『金融AI成功パターン』の第二章では、弊社や私が関わった地域金融機関との取り組みの中で個人融資のターゲティングAIについて解説しています。今回は、そのお話をいたします。
ターゲティングAIの基礎と考えかた

ターゲティングAIとはどのようなものですか?
金融ビジネスの営業施策では、すべてのお客様にアプローチを行うとコストや時間がかかってしまうため、優先順位をつけてアプローチするお客様を絞り込むことが一般的です。例えば、「ダイレクトメールの送付」という営業施策においては、預金残高や年齢などの条件から優先順位をつけてアプローチ、送付先を絞り込むことが多いです。

お客様に優先順位をつけ、アプローチ対象を絞ることでコストや時間を省く
*記事の文末に解説動画をご紹介しています。
優先順位をつける際、条件がシンプルである場合は獲得率が落ちてしまいます。これに対し、獲得率、つまりは精度を高めようと絞り込む条件を複雑にしてしまうと、人の手では3〜4件程度の条件を組み合わせることが限界となるほか、担当者の経験や勘に大きく依存してしまいます。
ターゲティング AI は、複雑な条件を組み合わせた優先順位付けを自動で行えるため、担当者の経験者に左右されることなく、精度や獲得率の高い絞りこみが期待できます。
実際にターゲティングAIは現場で利用されていますか?
特に個人融資の分野ではすでに活用されている金融機関が多い印象です。個人融資商品の中でも特にフリーローンやカードローンは、お客様の口座の動きなどから比較的ニーズの察知しやすい商品です。多くの銀行でニーズに合わせて、ダイレクトメールやアウトバウンドによる営業施策が行われています。このようなお客様一人ひとりの預金変動やローンの返済状況、入出金の動きを数カ月に渡ってターゲティングAIで分析することで、精度の高い資金ニーズのあるお客様を見付けることが可能です。
また、ターゲティング AI は顧客満足度の向上にも活用されています。将来、借り入れを行う確率を予測し、お客様が「借り入れしたい」と考えているであろうタイミングに合わせてダイレクトメールやアウトバウンド施策を行うことで、営業施策の獲得率、効果が向上するほか、お客様から「欲しいときに案内をくれる」と感じてもらい、ニーズのミスマッチを減らし、顧客満足度の向上も期待できます。
ターゲティングAIはどのようなデータから分析、予測を行っているのですか?
銀行の三大業務と言われる預金・融資・為替、それに伴うお客様の年齢、住所などの基礎情報に関するデータ、預金残高を記録しているデータ、融資の残高を記録しているデータ、入出金の履歴を記録しているデータなど、いわゆる勘定系データと呼ばれるデータを中心に利用しています。多くの銀行では、勘定系データをCRMデータとしてお客様ごとに情報を集約し、営業活動などに利用しています。個人融資のターゲティングAIの場合は、このCRMデータと、融資実行の履歴を記録した融資実行データの2つを使って構築を進めていきます。次の図をご覧ください。
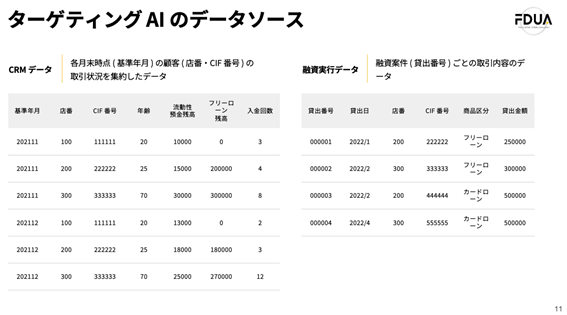
本ケースでのターゲティングAIのデータソース
※本データはひとりの顧客が保有する口座(本ケースでは、店番、CIF番号)はひとつとしている
*記事の文末に解説動画をご紹介しています。
これはCRMデータと融資実行データの例を示しています。CRMデータは、お客様ごとに、各基準年月の月末時点における年齢、預金残高、融資残高や、基準年月内の入出金回数などの情報が集約されています。融資実行データは、いつ、だれに、どの商品を、いくら融資したのかなどの情報が集約されています。
AIに渡すデータソースの基本的な考えかた
先ほどのデータソースをどのように加工していきますか?
まず、最終的にAutoMLに投入するデータ、ここではAI構築用データと言うこととしますが、AI構築用データをどう整理するか、4つの視点を解説します。
1:AI構築用データは1つのデータとして集約
本ケースではCRMデータと融資実行データと複数あるため、それぞれを集計・結合して1つのデータにします。
2:予測したい「ターゲット」と、予測するための「特徴量」を指定
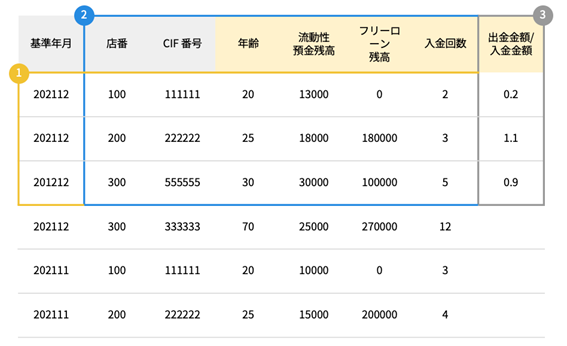
本ケースでは「ターゲット」はある基準年月からXヶ月以内に借入があるかどうか。「特徴量」はCRMデータの各列、また列同士の情報を組み合わせたもの、例えば出金金額 / 入金金額などを作成・使用します。
3:AI構築用データの1行あたりの粒度を定義
AI構築用データの1行あたりの粒度は、「ターゲット」の定義によって決定されます。本ケースでは「ターゲット」は各お客様がある基準年月からXヶ月以内に借入があるかどうかなので、お客様ごとに予測をしたいことになります。そのため、1行あたりの粒度はお客様、すなわち店番とCIF(シフ)番号となります。1行あたりの粒度が店番・CIF番号ということは、AI構築用データでは店番・CIF番号が重複してはなりません。極端な例ですが、店番100、CIF番号111111の顧客は「1」、店番200、CIF番号222222の顧客は「2」と名付けていき、AI構築用データ上に重複がないか?を確認します。
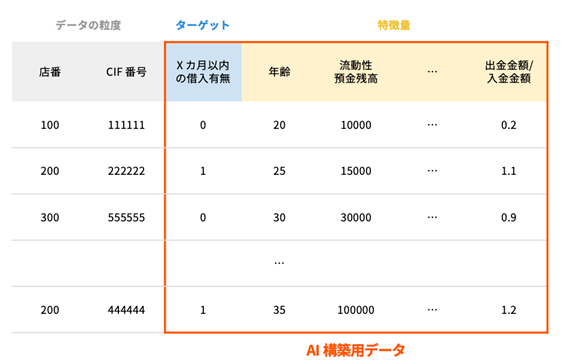
CRMデータと融資実行データを加工し、機械学習を実行するため、AI構築用データを作成していく
*記事の文末に解説動画をご紹介しています。
4:過学習を想定、予防する
最後に、本ケースにおいてAI構築用データの1行あたりの粒度となる、店番、CIF番号の列は削除する必要があります。本ケースは「顧客一人ひとりが現在からXヶ月以内に借入を行っていたかどうか」から「未来のXヶ月以内に借入を行う可能性があるか」の予測を目的としています。
本来、過去に借入を行った顧客の傾向、例えば預金残高が○○くらいで、入出金の頻度が○○くらいの顧客は借入確率が高い、といったことをAIには学習してほしいわけですが、店番、CIF番号の列が含まれた状態でAIを構築すると、店番が○○でCIF番号が○○だから借入確率が高いといった学習をしてしまう可能性があります。これを防止するために、店番・CIF番号の列は削除する必要があります。
人に指示を与えるときと同じですね。
そうですね。AIは飛躍的に進歩していますが、データを与えるだけで「自動で期待通りの結果を出してくれる」ものではありません。人が「何をどうやって欲しいのか?」を明確にし、的確に指示と情報を与える必要があります。
精査したデータを実際に加工していく上での着眼点、工夫
次に具体的に本ケースでどうデータソースを加工していくかを解説します。
加工の手順は次の4つで進めていきます。
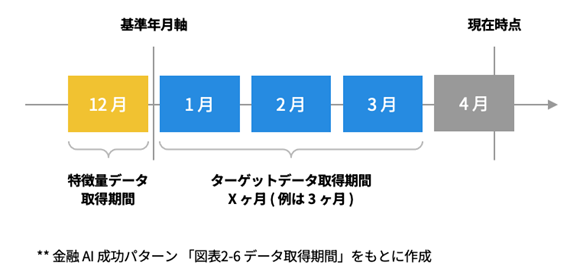
1:データの取得期間の決定
融資実行データ、CRMデータ、それぞれのデータ取得期間を決定します。つまりは、いつからいつまでのデータを基に、いつからいつまでの予測を立てていくか。今回は過去の預金や入出金の変動から将来借入を行うかどうかを予測することが目的です。
a. ターゲット「 X ヶ月以内の借入有無」の X の期間を決定する(今回の場合、X=3とします)
b. 現在時点から少なくとも X ヶ月より前の任意の基準年月を基準年月軸として 1 つ決定する(今回の場合、2021年12月を基準年月軸とします)
c. b.で決定した基準年月軸から将来 X ヶ月以内の貸出日をターゲットデータ ( 融資実行データ ) の取得期間とする(今回の場合、基準年月軸である2021年12月から3ヶ月の2022年1月、2月、3月となります)
d. b.で決定した基準年月軸を特徴量データ ( CRM データ ) の取得期間とする(今回の場合、基準年月軸の2021年12月となります)
つまりは3ヶ月先までを予測するためには少なくとも「現在から3ヶ月以上前」の情報を特徴量として、AIを構築する必要があると言うことです。Xヶ月以内の借入の回数、金額を分析することで「Xヶ月以内に○○万円の借入を行う可能性がある」と考えることができます。
2:融資実行データからターゲットデータを作成
次に融資実行データからターゲットデータを作成します。下記の図をご覧ください。1で決定した融資実行データの取得期間、つまりは2022年1月、2月、3月の貸出日、また今回借入を予測したい融資商品、今回はフリーローンの融資実行のデータを抽出し、データから店番、CIF番号の列のみを抽出します。
予測の基になるデータを決定、上記では「1〜3月」をターゲットデータ取得期間と決めている
*記事の文末に解説動画をご紹介しています。
このとき、お客様によっては1ヶ月に複数借入を行っている可能性もある。つまりはデータソース上で店番、CIF番号の重複が出る可能性があるため、その場合は重複を削除します。最後に、すべての値が1のターゲット「Xヶ月以内の借入有無」の列を追加します。これでターゲットデータの作成は完了です。
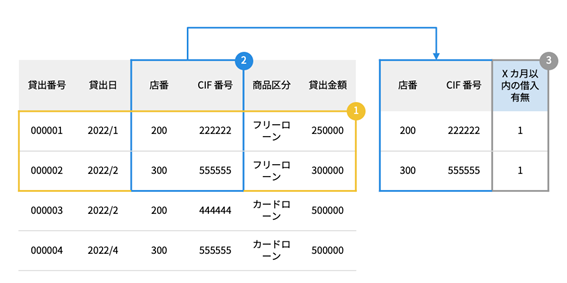
ターゲットデータの作成イメージ
*記事の文末に解説動画をご紹介しています。
① 融資実行データから、決定したデータ取得期間と、ターゲットの対象となる融資商品のデータのみ抽出
② ① で抽出したデータから、店番と CIF 番号の列のみ抽出し、店番と CIF 番号の重複がある場合は、重複を削除し、店番と CIF 番号でユニークなデータを作成
③ ② で作成したデータに、すべての値が 1 のターゲット列「 X ヶ月以内の借入有無」を追加
3:CRMデータから特徴量データを作成
次にCRMデータから特徴量データを作成します。まずは、1で決定した特徴量データの取得期間に沿ってデータを抽出します。今度は商品特性を追加していきます。今回はフリーローンなので、フリーローンの借入条件である年齢や住所、人格区分等の条件に沿ってデータを抽出します。
次に基準年月を除く店番とCIF番号、その他特徴量として有効な列を抽出し、さらによりAIの予測精度を向上させるために欠損値補完や特徴量エンジニアリングを実施します。ここの例では、出金金額 / 入金金額といった、出金金額と入金金額の列同士を割り算した列を作成しています。
これで特徴量データの作成は完了です。
特徴量データ作成のイメージ
*記事の文末に解説動画をご紹介しています。
① CRM データから、決定したデータ取得期間と、ターゲットの対象となる融資商品の商品性 ( 年齢などの条件 )に応じてデータを抽出
② ① で抽出したデータから、店番と CIF 番号、その他特徴量として有効な列を抽出
③ ② で作成したデータをもとに、欠損値補完や特徴量エンジニアリングを実施
4:ターゲットデータと特徴量データを結合・加工して、AI構築用データを作成
最後に2、3で作成したターゲットデータと特徴量データを結合します。結合の際は、特徴量データにターゲットデータを結合する流れであれば、left outer join 、ターゲットデータに特徴量データを結合する流れであれば、right outer join など左から右への順にしておきます。
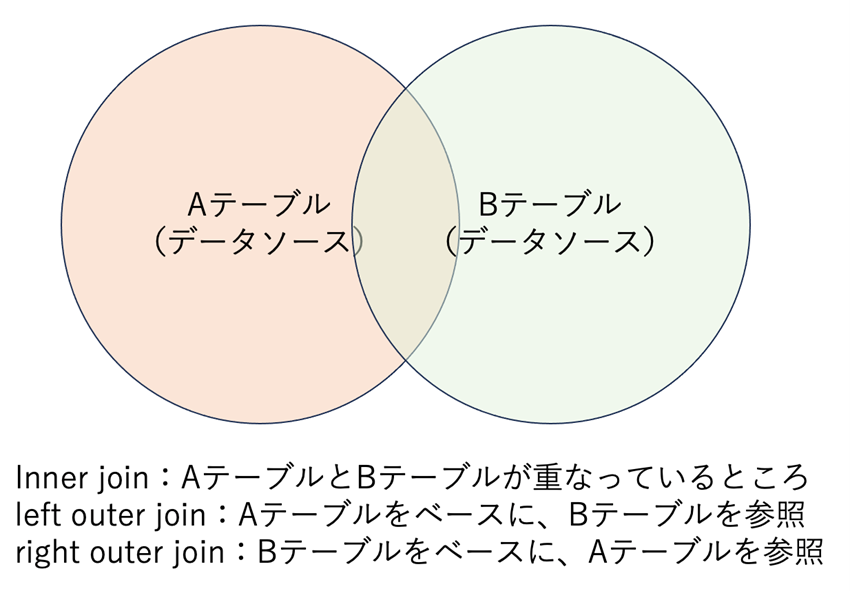
Aが特徴量データ、Bがターゲットデータである場合、「left outer join」を行うと特徴量データをベースにして、ターゲットデータを結合する。つまり、特徴量データに“ない”がターゲットデータに“ある”情報は適応されない=削除される
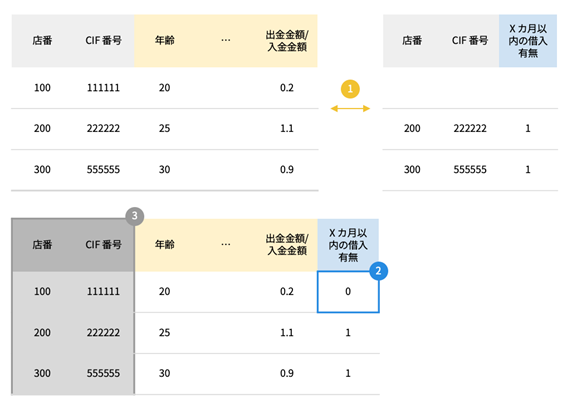
そして、重複や欠損の処理。このケースでは、もしターゲットデータの期間内に借入を行っていない場合は、ターゲットの「Xヶ月以内の借入有無」の列の値が空欄となってしまいますので、空欄は「0」で補完します。そして、このAI構築用データを作成するため、個人を識別するために残していた店番とCIF番号を削除してAI構築用データは完成です。
AI構築用データ作成のイメージ
*記事の文末に解説動画をご紹介しています。
① 特徴量データを全量取得するように、ターゲットデータと店番・CIF 番号をキーに結合
② ① で結合を行うと、ターゲットデータにない店番・CIF 番号のターゲット「X ヶ月以内の借入有無」の値は欠損になってしまうため、0で補完
③ 最後にデータの粒度となる店番・CIF 番号の列を削除
複雑そうに見えますが、「AIに、どのようなターゲットに対して、どのデータから予測して欲しいか」と考えていくと、データソースをどう加工すれば良いのか見えてきそうですね。
そうですね。先ほども言いましたが、人が目的と情報を明確にして、指示を与えることでAIは機能しやすい。AIだけに任せるのではなく、人とAIが協力していくことをイメージしてください。
そして、まず人が行うべきことは「どんなデータを作るのか、作りたいのか」を考えること。冒頭に挙げたAI構築用データの4項目は、金融に限らずAI構築をする際に目安となるため、活用いただきたいです。
1:AI構築用データは1つのデータとして集約
2:予測したい「ターゲット」と、予測するための「特徴量」を指定
3:AI構築用データの1行あたりの粒度を定義
4:過学習を想定、予防する
この4項目を確定させれば、目的が定まります。この目的に向けて、どうデータを加工すれば実現できるのか?を考えていくことができると思います。
モデリングを実施する上で、確認しておきたいこと
これで予測の基となるデータが完成しました。次は何をしますか?
このデータソースを使って、今回はAutoML(=Automated Machine Learning)を利用してAIを構築していきます。AutoMLはAIを利用した分析を行う際、各種タスクが自動化できる技術です。このAutoMLに先ほどのAI構築用データを投入し、モデリングを実施していきます。
基本的にAutoMLは自動で最適な設定でモデリングを実行してくれますが、これらの項目について、設定がされているか確認しておくと良いでしょう。本ケースでは以下を確認しました。
・機械学習タスク: 二値分類
・アップロードデータ: AI 構築用データ
・ターゲット:X ヶ月以内の借入有無
・特徴量の型:各特徴量が数値・カテゴリなど、適切な型として認識されているか
・検定方法:層化抽出法による交差検定
目的は「ターゲットに対して、特徴量から予測を出していく」こと。そのためには、前段階、AI構築用データを如何に作り込むことができるかが鍵となります。そう考えれば、シンプルになっていくのではないでしょうか。
「機能しているのか?精度はどうか?を検証していく
「AI構築が上手くいかない」と言う声はよく届きますが、「上手く行っていないな」と思った際に鍋倉さんはどうしていますか?
大切なことですが、AIの構築は一回では上手くいかないことがほとんどなんです。ただし、その原因の多くはAI構築用データです。だからこそ、これまで「データソース」について説明いたしました。
本ケースで利用しているAutoMLはモデルのインサイトを可視化してくれる機能が備わっていることが多いです。「上手くいっていない」と感じた際は、インサイトから予測のズレに繫がりそうな”データ”を見付けて、AI構築用データの改善をします。
予測のズレに繫がりそうなデータとは、例えばどの特徴量がどの程度AIに影響を与えているのかを示すFeature Importanceで、特定の特徴量だけが顕著に影響を与えているケースを見ることがあります。つまりは、現在の予測結果を出すために貢献度の大きい特徴量を精査していく。実は含めてはいけない特徴量であった、など気付けます。
そのほかに、「ここも見てみると良いです」はありますか?
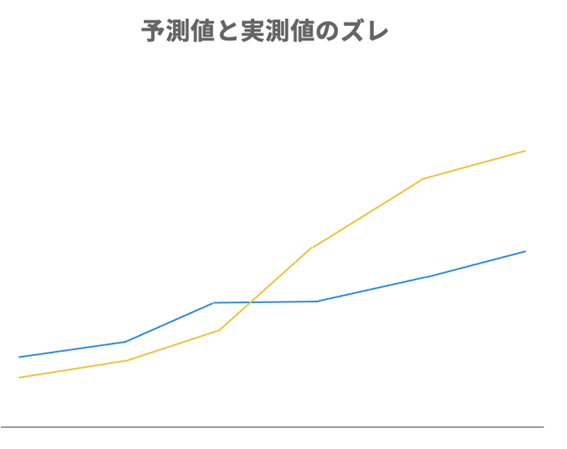
例えば下の図のように、予測値と実測値を並べたとき、明らかに傾向が違って出てくることがあると思います。
*記事の文末に解説動画をご紹介しています。
これはつまり「AIがうまく予測できていない」ということです。この場合は、値・レンジでデータを分割してAIを複数構築することで、AIの精度改善が期待できる場合があります。
「原因はAI構築用データにある」=だからまずはデータソースを見直してみる。反面で実測値と予測値を並べて「どこで予測にズレが出ているのか」を特定する。なるほど、鍋倉さんが「AIの構築は一回では上手くいかない」と仰るのは、動かしながら精度を高めていくものなんですね。
AIの精度検証は、実際に施策を行って検証する実務検証と過去のデータで検証する机上検証があります。 AUCは机上検証におけるAIの精度指標の1つであり、多くのAutoMLで自動的に計算をしてくれます。

机上検証、AUC値の目安
*記事の文末に解説動画をご紹介しています。
AUCの値だけでAIの精度を測ることはできませんが、直感的に1に近ければ精度がよい、0.5に近ければ精度が悪いと判断することができます。とりあえずは0.6-0.8あたりを目指すといいでしょう。
また、実務検証においてはマーケティング経験者にはお馴染みの「ABテスト」がAIでも有効です。データ抽出を既存手法、AI利用の2つの方法で行い、結果を突合して精度を比較検証します。
「準備に手間をかけるほど、運用は楽になる」
ここまで長い道のりでしたが、目的を定め、データソースを整理し、AIに投入。検証の準備も整ったのでいよいよ運用ですね。運用をしていく上の着眼点など教えていただけませんか?

おさらいも兼ねたAIの運用フロー
*記事の文末に解説動画をご紹介しています。
実は今回お話ししているターゲティングAIにおいて、AIの運用はそこまで複雑ではありません。直近の基準年月のCRMデータを取得して、特徴量データの作成と同じようなデータ加工を施し、AIで予測します。アウトプットとして各顧客、つまり店番・CIF番号ごとに借入確率が出力されますので、借入確率の高い順から施策対象の数だけ取得し施策を実施していき、検証を行っていく。準備で手を掛けるほど、運用で行うことは減っていく、と考えてください。
ただし、AIでターゲティングリストを作成・運用するだけがAIの運用ではありません。
昨今はMachine Learning Operations、略してMLOpsと呼ばれる、AIの監視・管理が重要とされています。その中で、まず着目してもらいたいのは「データドリフト」です。
データドリフトは、AIに入ってくる予測用のデータが、AIを作ったときのデータと比較して変化していきていないかを監視するものです。極端な例ですが、運用をしている途中で「こういう情報もあれば精度が高くなるのでは?」とデータソースを追加するなど。「いままでは万円区切りだったが、千円区切りにしました」、こういった小さな変化もAIに伝えなければ精度に影響してしまいます。
大きな部分から具体的なケースまでお話しいただきありがとうございます。最後にひと言いただけますか。
このほかにも精度劣化、つまりはAIの予測と実際の結果が落ちてきていないかを監視するほか、システムが適切に連携できているのかなども確認していく必要があります。AIは日進月歩で進化しています。それと同じように、社会や市場も変化しており、適宜人の手を介して調整をする必要があります。また、適切に予測ができていたとしても、例えばインターネットの回線障害のように、システム間に障害があれば予測結果が出力されません。
「AIは難しい」、そう仰るかたには「そんなことありません!」と伝えたいと常々考えています。砂漠で落とした指輪をAIに探し出してもらおうとしてしまっていませんか?いつ落としたことに気付いたか、どのルートを歩いていたのか、可能な限り思い付く情報を書き出し、「見つけ出す」ために必要な情報だけ抽出することでAIは指輪を早く見つけ出す強力にサポートしてくれます。
是非本記事や書籍「金融AI成功パターン」から、AI活用のヒントを見つけ出して欲しいです。
金融データ活用推進協会 著
『金融AI成功パターン』
大好評 発売中!
「FDUA 金融データ活用推進協会タイアップ企画」動画
◆金融データ活用推進協会 企画出版 書籍『金融AI成功パターン』”第二章 ターゲティングAIパターン”◆
セゾンテクノロジー公式youtubeチャンネルにて、
第二章の執筆を担当したSBIホールディングス株式会社 鍋倉由樹様の解説動画をご紹介しています。
併せてご覧ください。


