Developer Blog Series Vol.5_0 - Data Visualization and Analysis -


Vol.05_0 AWS re:Invent from an Analtytics Perspective (2022 Edition)
This is the fifth article in our series on data analysis and visualization, but this time we're going to bring you something a little different.
I participated in AWS re:Invent, which was held in Las Vegas from November 27th to December 2nd, 2022.

I could write a lengthy report on the excitement and fun I had there, but
That would not be the job of an important task promotion leader, so I will talk about my area of expertise.
I participated in the event with the theme "re:Invent from an Analytics Perspective."
In this article, I would like to report on this topic.
- As an aside, the reason why I'm publishing this out-of-season article now is because I really wanted to write my last article as soon as possible.
Previous article: Thinking about data quality
I intend to write about truly important things here, so even if you have just skimmed through it once, I would encourage you to read it again and again.
Activity Summary

To help you understand what I'm looking at and writing this article, I'll first provide a summary of the sessions I attended.
I attended a total of 12 sessions over five days.
Since the theme is Analytics, when viewed by track, there are many sessions related to Analytics and related technical elements.
As a result of these sessions, I would like to share my thoughts from the following two perspectives.
- 1. Scope of “Analytics”
- 2. A Zero ETL future…
- The outline of this report was created locally, so it is noisy and full of alphabets, but please take it in as a sign of how excited I was.
Scope of Analytics
The first thing I noticed was that the scope of what is meant by analytics is different in Japan.
There are no clear definitions for either, so this is just my personal experience, but I don't think there's much difference between them.
I never heard these terms when I was there, but it is easier to explain using the concepts SoR, SoE, and SoI, so I will use these.
- SoR: System of Records - a system for recording data such as accounting systems, HR and order mission-critical system, core system
- SoE: System of Engagement - Systems that emphasize connections with users, such as CRM and SFA
- SoE: System of Insight...System for obtaining insights such as BI
Analytics in Japan
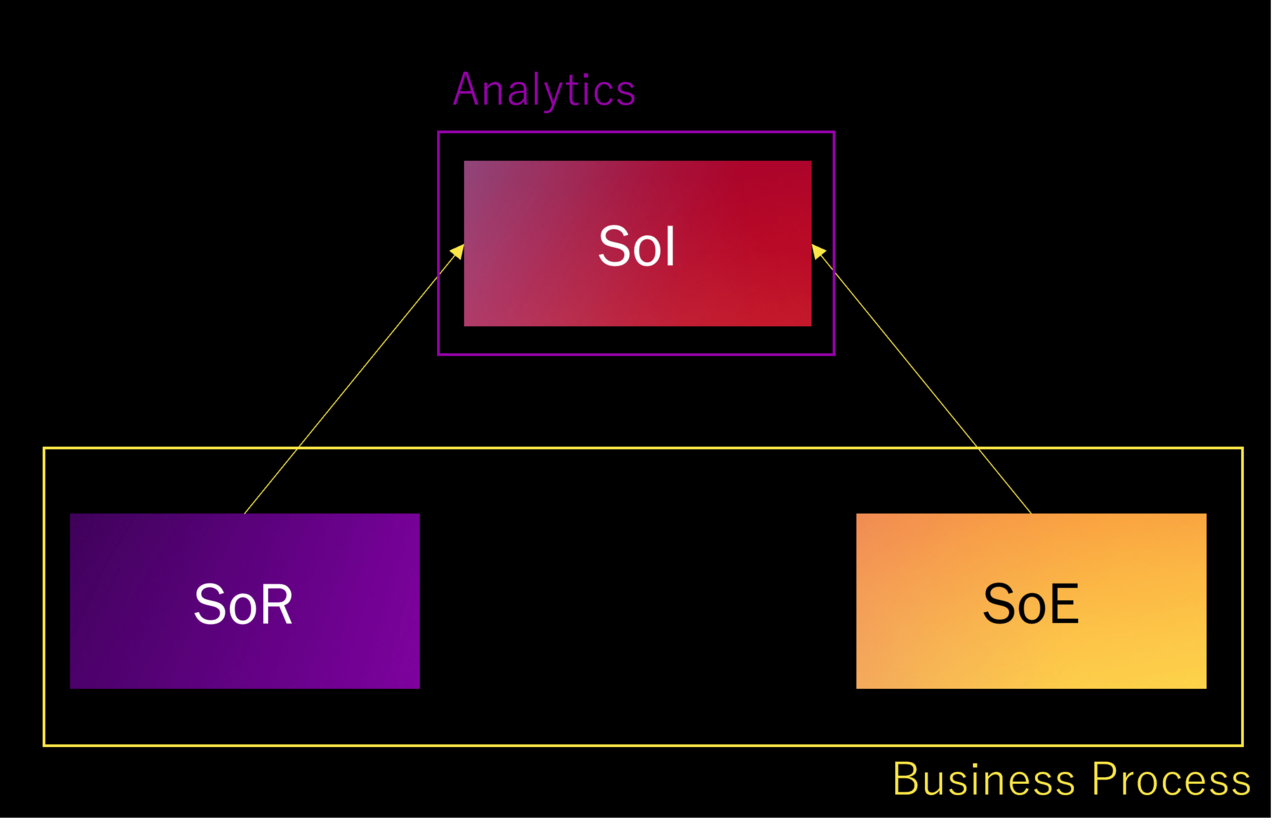
I have illustrated Analytics in Japan.
First of all, business processes are basically formed by the SoR and SoE mechanisms.
SoI integrates this information and serves as the basis for analysis, and in Japan, analysis performed on this SoI is called Analytics.
If anything is learned from the analysis, it is fed back into the business process manually in the form of measures.
In other words, in the system domain, SoI = Analytics, and Analytics is an external concept to business processes.
Analytics in the US
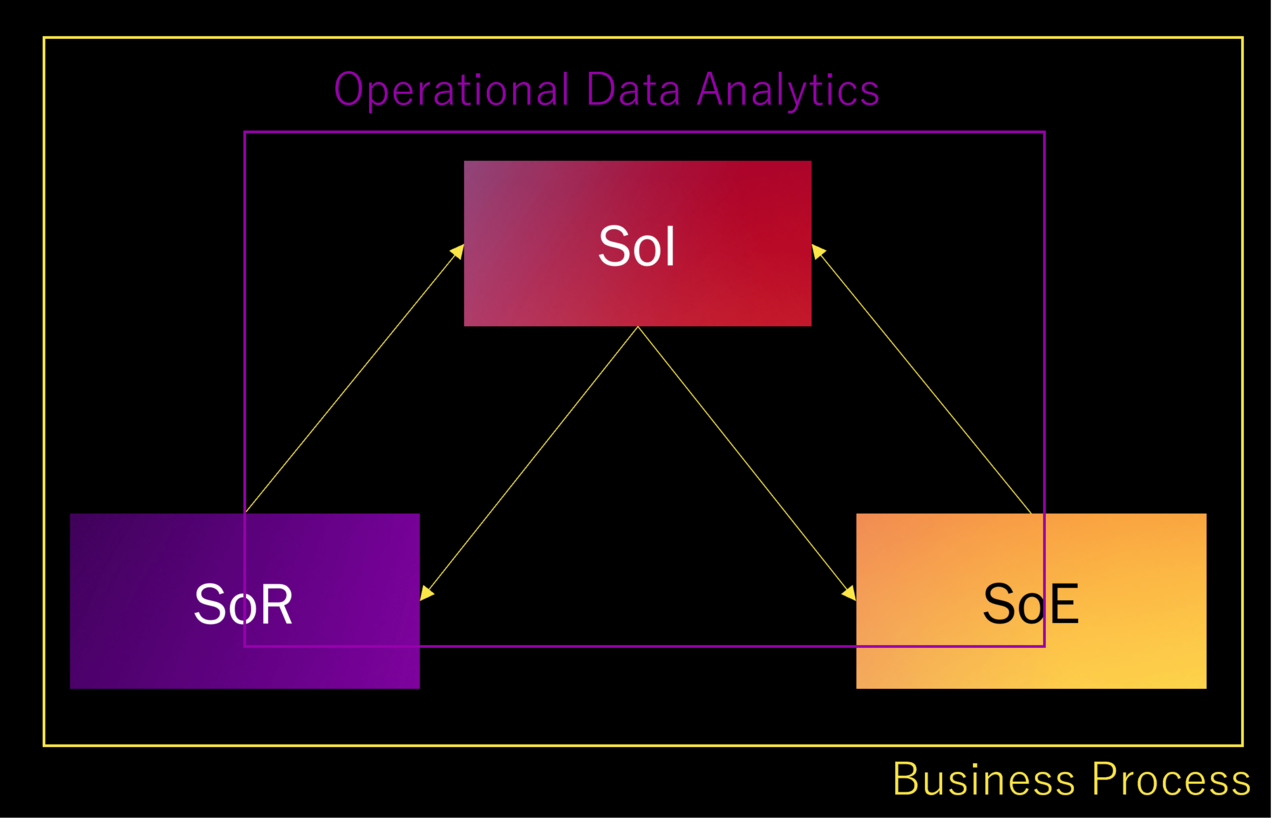
Next, I will share with you the image of analytics in the US that I gained while I was there.
First of all, the biggest difference is that there are return arrows from SoI to SoR and SoE.
This means that the process of feeding back the results obtained in SoI to SoR and SoE is automated.
This is called Operational Data Analytics, which is essentially Analytics.
Data processing across SoI, SoR, and SoE is also included in the scope of Operational Data Analytics.
In terms of its relationship to business processes, Analytics can be thought of as being included within the business processes.
- Please note that this content is merely an image, and in reality, there are local examples in Japan where "US-style analytics" has been realized.
For example, demand forecasting-based automatic ordering in the retail industry and abnormality detection in factory automation in the manufacturing industry.
Unfortunately, in many cases, the idea is to "introduce an automatic ordering system," so I don't think it can be translated into this concept.
Impressions
I believe that in the future, the key in Japan will be to create and propose use cases that point back to SoR and SoE.
Currently in Japan, there is a lot of data that is being put onto the cloud for the first time in order to be stored in a DWH.
Because there is data that can only be obtained through DWH, domestic companies are also seeing signs that the number of systems centered around DWH will increase in the future.
We would like to discuss with our customers what kind of data can be fed back into the business process.
Also, when considering the origin of the return arrow, if the base point of the arrow is only BI, there will be a limit to the information that can be returned.
When we consider where the starting point is, there is no doubt that the importance of AI and ML will increase.
A Zero ETL future…
There was a shocking message in the Key Note on the second day.

To roughly summarize, the idea is that ETL pipelines are painful for developers, so we're creating a future without ETL.
This is in an Analytics context, so keep that in mind.
Below are some excerpts from presentations related to Zero ETL from my personal perspective.
-
Data Ingestion
- Amazon Aurora zero-ETL integration with Amazon Redshift | 11/29 Keynote
- Informatica Data Loader for Amazon Redshift | 11/28 Keynote
- Amazon Redshift now supports auto-copy from Amazon S3 | 11/30 Keynote
-
Data Preparation and Data Transformation
- Amazon Redshift integration for Apache Spark | 11/29 Keynote
- Amazon Athena for Apache Spark | 11/30 Keynote
-
others
- Amazon Data Zone | 11/29 Keynote
What is Data Ingestion?
Although it simply says "something related to Data Ingestion," let me first explain what Data Ingestion is.
What this relates to, among other widely known concepts, is the L in ETL, which stands for loading data.
First of all, it has been said for quite some time that it is ELT and not ETL.
This is a matter of order; rather than Transform and then Load, the idea is to Load first and then Transform.
This must be understood in conjunction with the concept of "schema on read," which means that the data importer does not have to define the format, but rather the user can extract it in the format they want.
If we add the concepts of time and responsibility decomposition points to this explanation, it becomes clear that the person who imports data into a data store such as a DWH will simply put it in as is, and the person who uses the data, such as a data scientist, will then transform it into the form they want and load it when they want.
If you just want to input data directly into a DWH, you'd want it to be automatically imported with just a few settings.
This is how Data Ingestion was born (maybe).
The easiest example to imagine is Snowflake's Snowpipe.
It loads data into the DWH in response to events in object storage such as S3 and Blob Storage.
In reality, the definition of the concept is vague, so data virtualization mechanisms such as Azure Synapse's Polybase and streaming processing mechanisms such as Apache Kafka are sometimes referred to as Data Ingestion.
Don't fight with Data Ingestion
Considering how the concept of Data Ingestion emerged, I don't think ETL needs to compete in this area.
Among the services related to Zero ETL Future that I introduced earlier, there were several related to Data Ingestion.
I believe this is a given and not a new threat.
At the moment, Data Ingestion is mainly a discussion within a single cloud, but if we look a little further outside and consider how to get the data to S3, or in the case of multi-cloud, this becomes the main battlefield for ETL.
In Japan in particular, the majority of source data is still on-premise.
Looking at the message "Zero ETL Future" from that perspective, I think it's not ETL manufacturers like us who feel threatened by this announcement, but platform providers like Snowflake and Treasure Data who were ahead of the curve by wrapping AWS (because they had already implemented the Data Ingestion mechanism).
Architecture talk (skip if you're not interested)
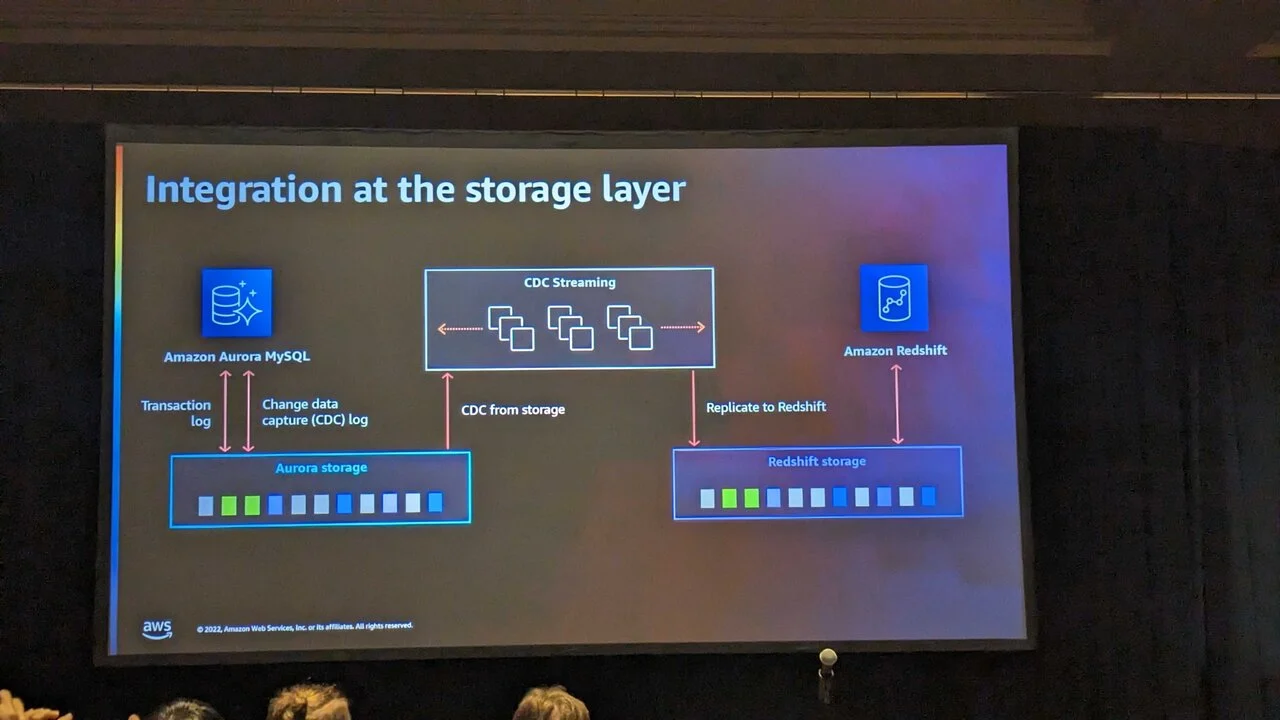
Architecturally, Amazon Aurora zero-ETL integration with Amazon Redshift uses Aurora's transaction log to synchronize at the storage layer using log-based Change Data Capture (CDC).
CDC is a mechanism for extracting differences in data.
To put it simply, Amazon Aurora zero-ETL integration with Amazon Redshift means that Aurora is automatically synchronized with Redshift, using differential synchronization.
There are various methods for CDC, but the most commonly used method is a timestamp-based method called Audit Columns.
Currently, the fastest mechanism is log-based CDC, which synchronizes differences based on the so-called redo log.
Amazon Aurora zero-ETL integration with Amazon Redshift is log-based and transfers data at the storage layer.
This is a significant improvement over the previously implemented third-party Data Ingestion functionality.
I think third parties, who thought they had been ahead of the game until now, must feel like they have been overtaken all at once.
Impressions
I was reminded once again that the key word in ETL is cross-border.
Once you get on the cloud, you're faced with a worldview where everything is connected.
- On-premise-cloud/cloud-to-cloud cross-border
- Arrows returning from SoI to SoR and SoE (crossing territorial boundaries)
This is the key point.
As always, preparation and transformation will be key areas of competence, but I think the Amazon Redshift integration for Apache Spark will be in direct competition with these.
(Cloud ETL is already commonly combined with Jupyter Notebook or Databricks Notebook running on Spark, but this is the context in which Zero ETL will become a reality.)
However, although Spark is fast, it also comes with the challenge of running out of memory, and considering that there are people who cannot write SQL in the first place, I predict that ETL and Zero ETL will coexist in this area.
(Let's leave aside the fact that if they coexist it won't be zero.)
Personally, I think the message "Zero ETL Future" is a stylish way to present it.
Conclusion
Finally, I'd like to talk a little bit about the event itself.
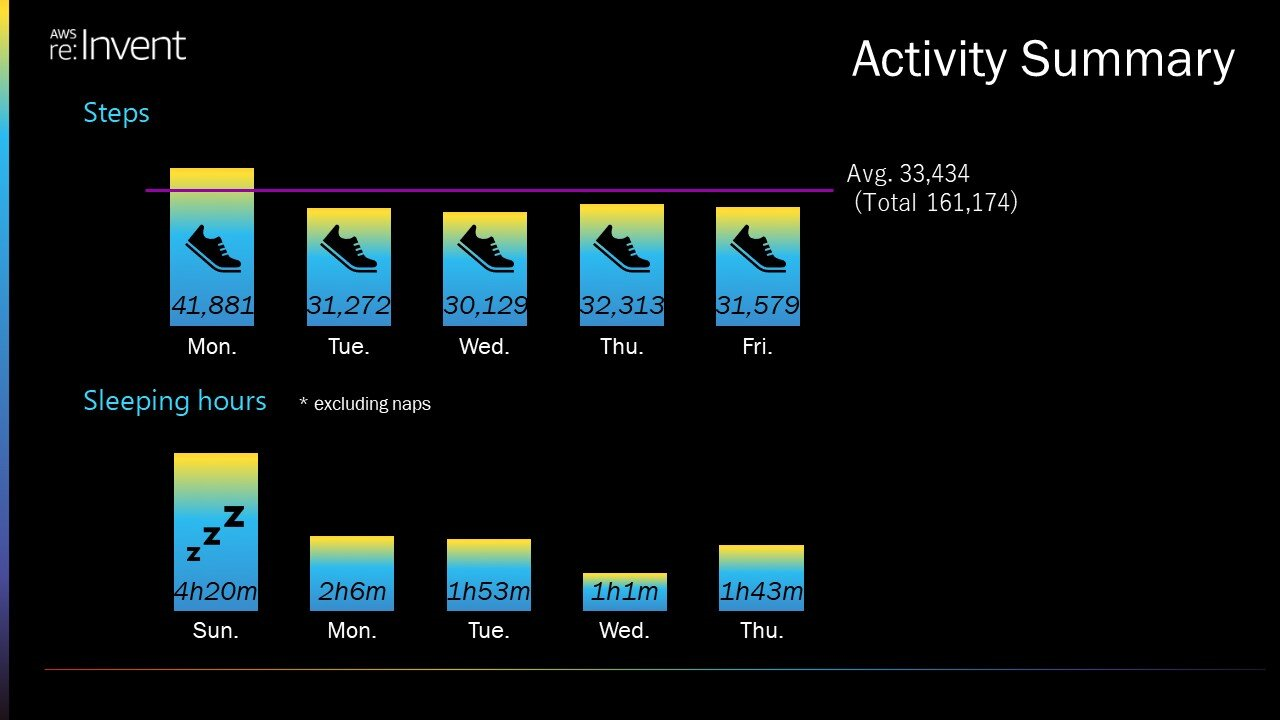
This is a picture that shows the number of steps I took and the amount of sleep I got while I was there. I spent my days walking a lot and not sleeping at all.
Although I caused some inconvenience to the other members around me, the five days away from my daily work and focused on technology were very stimulating.
I would like to express my gratitude once again for this opportunity, and I hope that many others will be able to experience the same excitement.

This is the view I saw when I ran 5km down Frank Sinatra Drive, the main street in the AWS re:Invent 5K.
The man I ran with this time was a non-engineer working for United Airlines.
Although we spoke in broken Japanese, he said something like, "Everyone needs to understand technology, it doesn't matter whether you're an engineer or not."
I agree that what this man is saying doesn't really matter what the current level of technical ability is.
I wrote this story in the hope that it will inspire even one more person to want to go if they have the opportunity.
Thank you for reading to the end.
The person who wrote the article


